1Renaissance Computing Institute, 2North Carolina State University, 3Lawrence Livermore National Laboratory
Problem desciption
ScalaTrace: Reconfigurable Scalable Performance Analysis
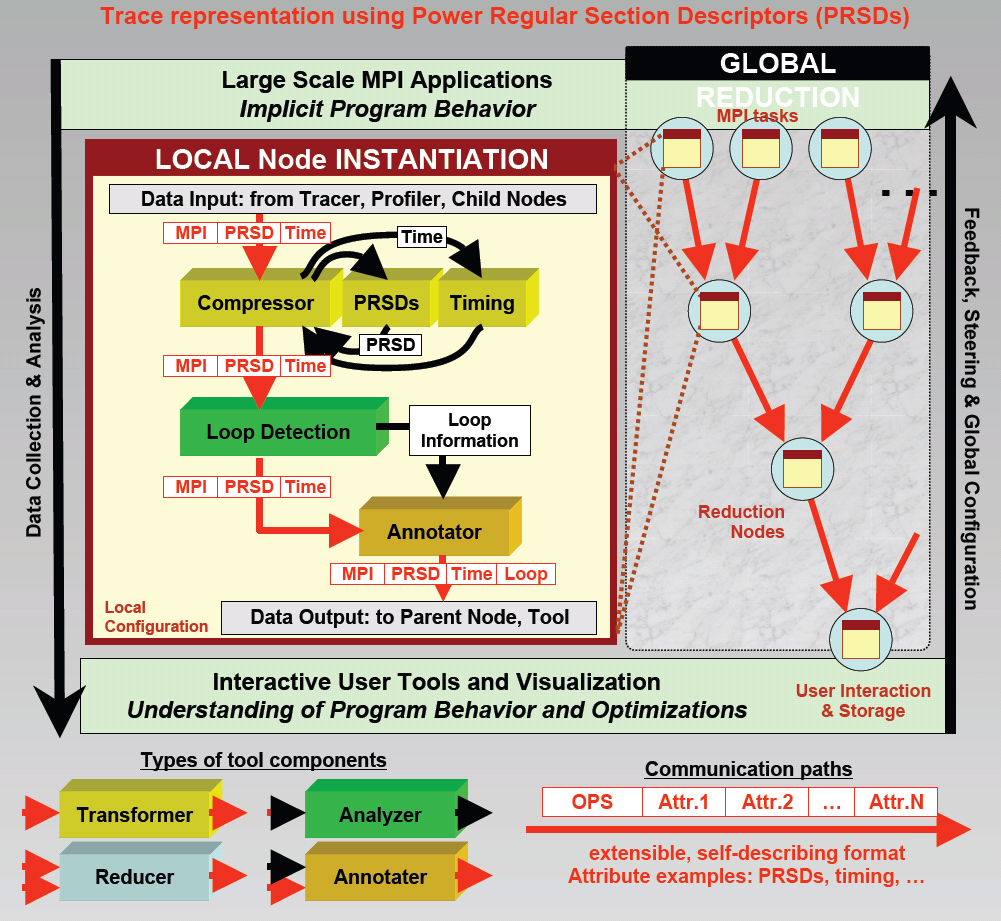
|
ScalaTrace compression framework provides:
|
ScalaReplay: Replay Using Histogram Timing Annotations
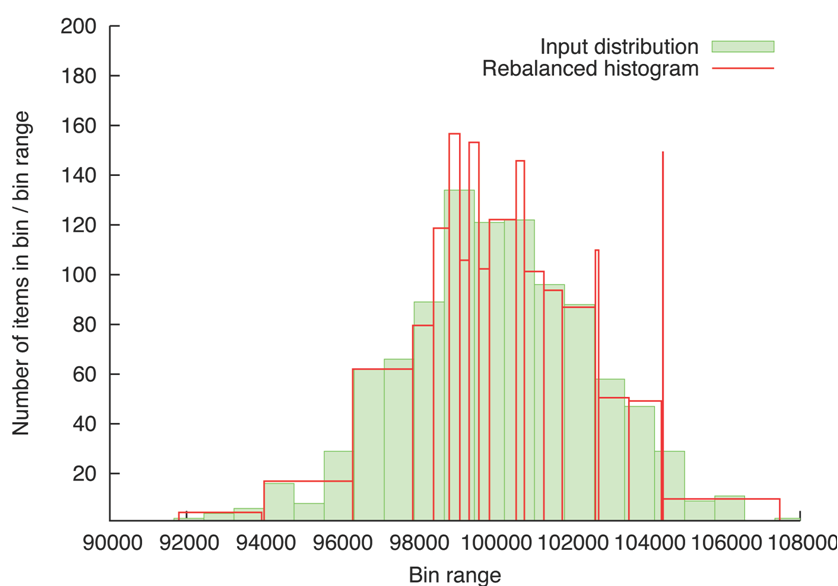
Figure: Bins generated for synthetic input span entire range with similar sample counts |
Idea: preserve time in compressed traces
|
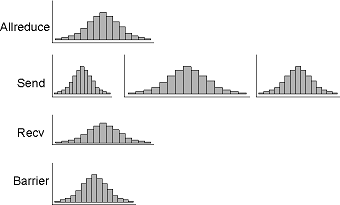
Number of histograms per record depends on the number of possible call paths |
Path-sensitive histograms
Sample:
MPI_Allreduce (..);
for (..) {
for (..) {
MPI_Send (..);
MPI_Recv (..);
}
MPI_Barrier (..);
}
|
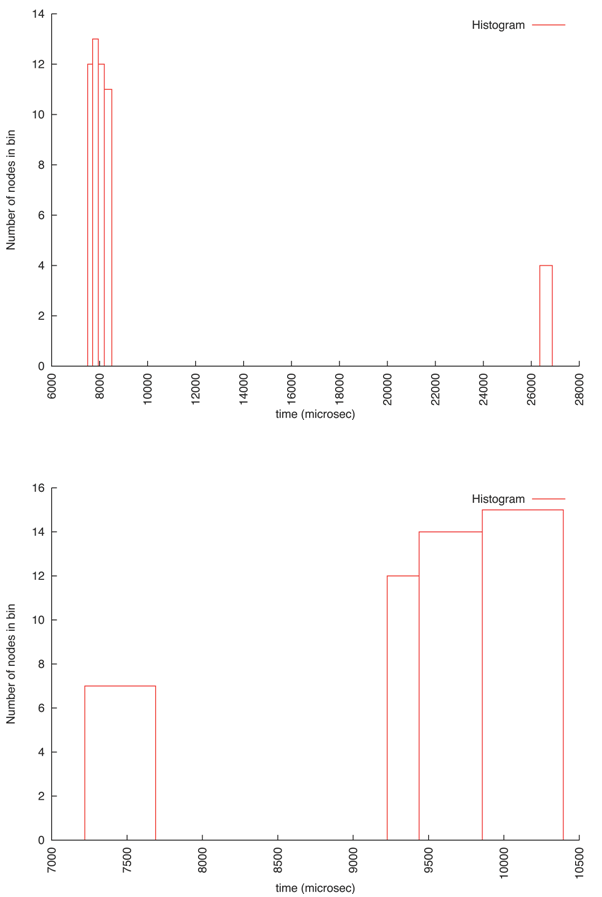
Sample bimodal distribution from UMT2k collectives |
|
|
Trace sizes (NAS Benchmarks and UMT2K) 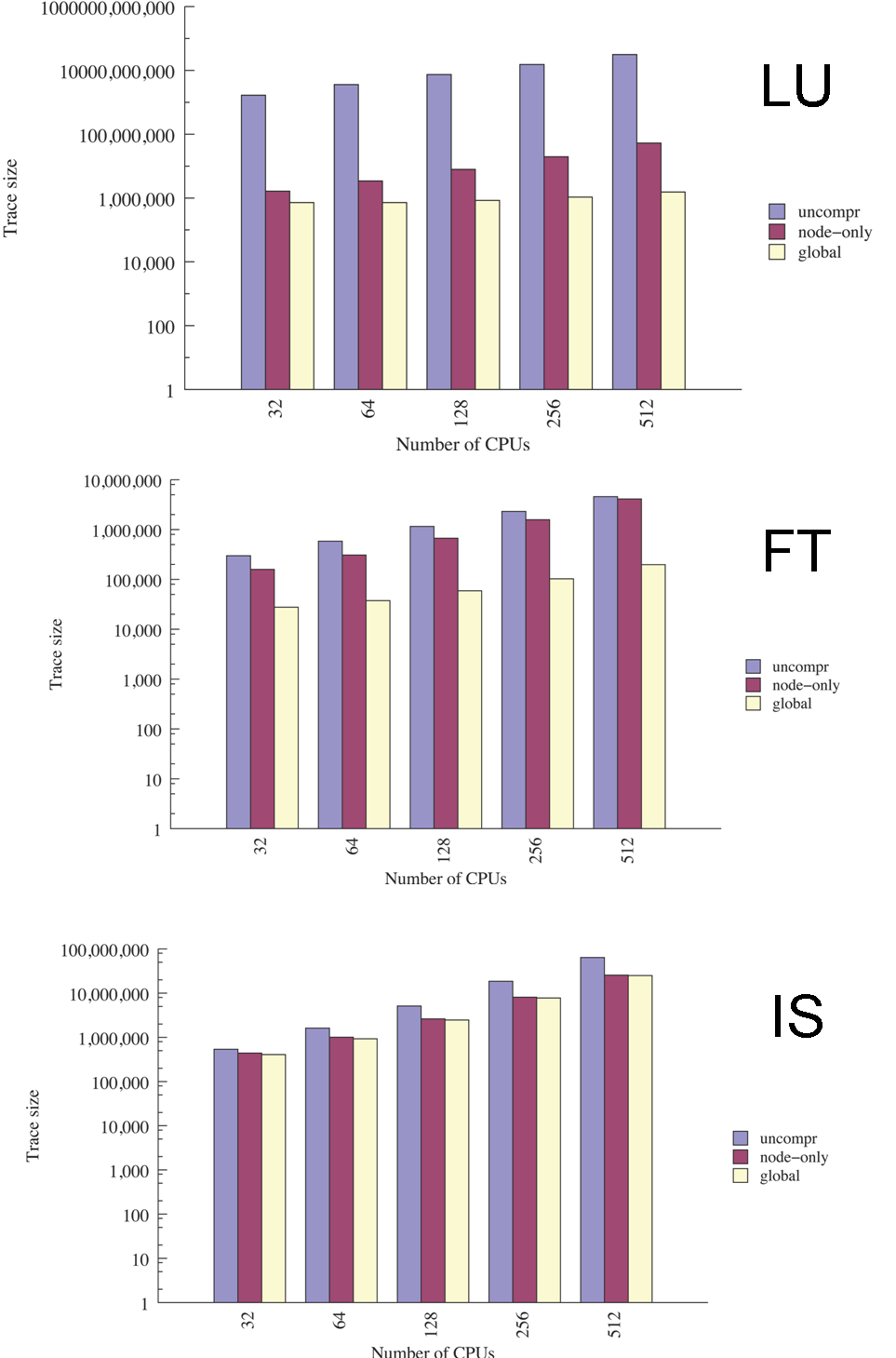
|
The benchmarks fall into three categories:
|
|
Replay Accuracy (NAS Benchmarks and UMT2K) 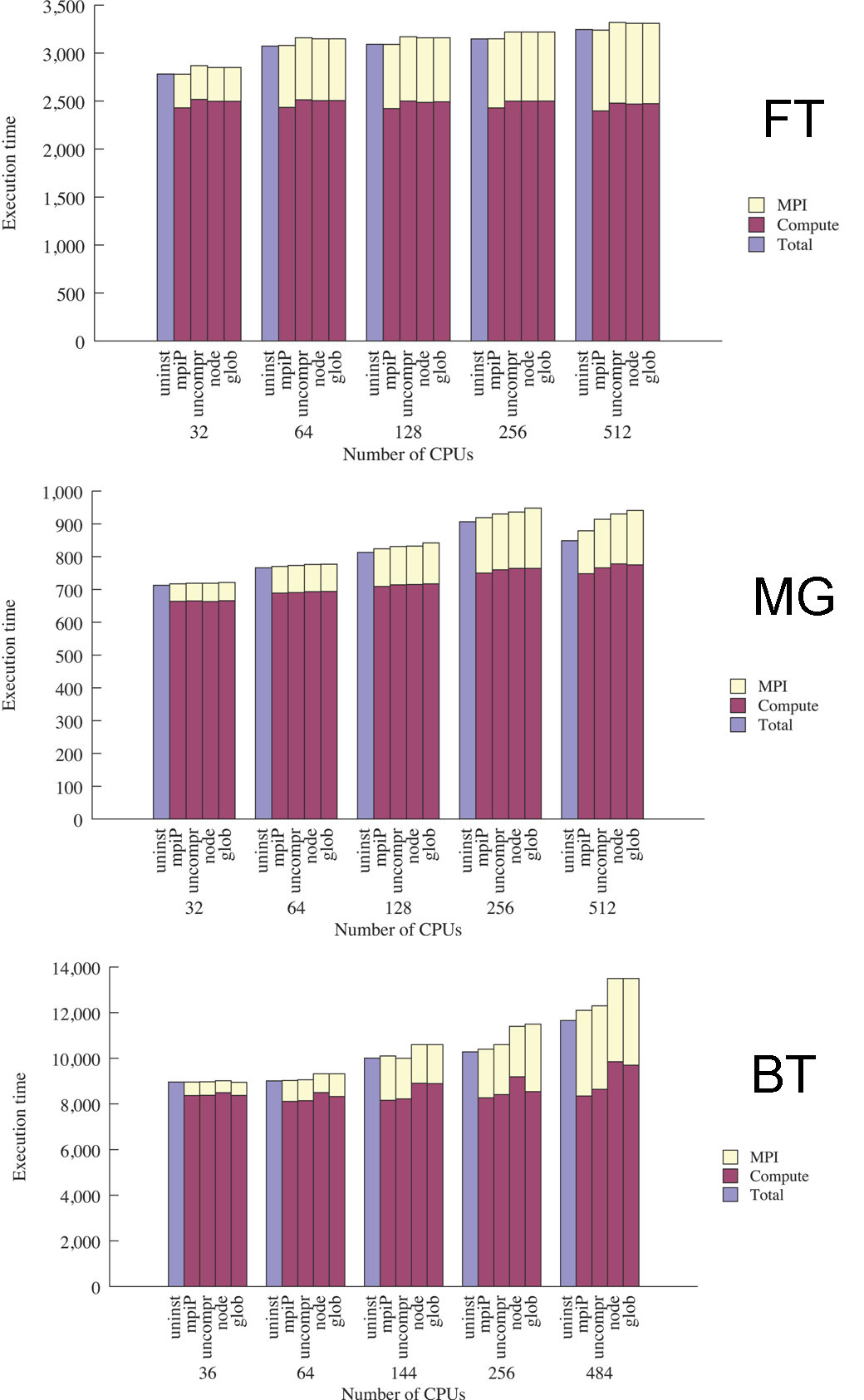
|
The benchmarks fall into three categories:
|
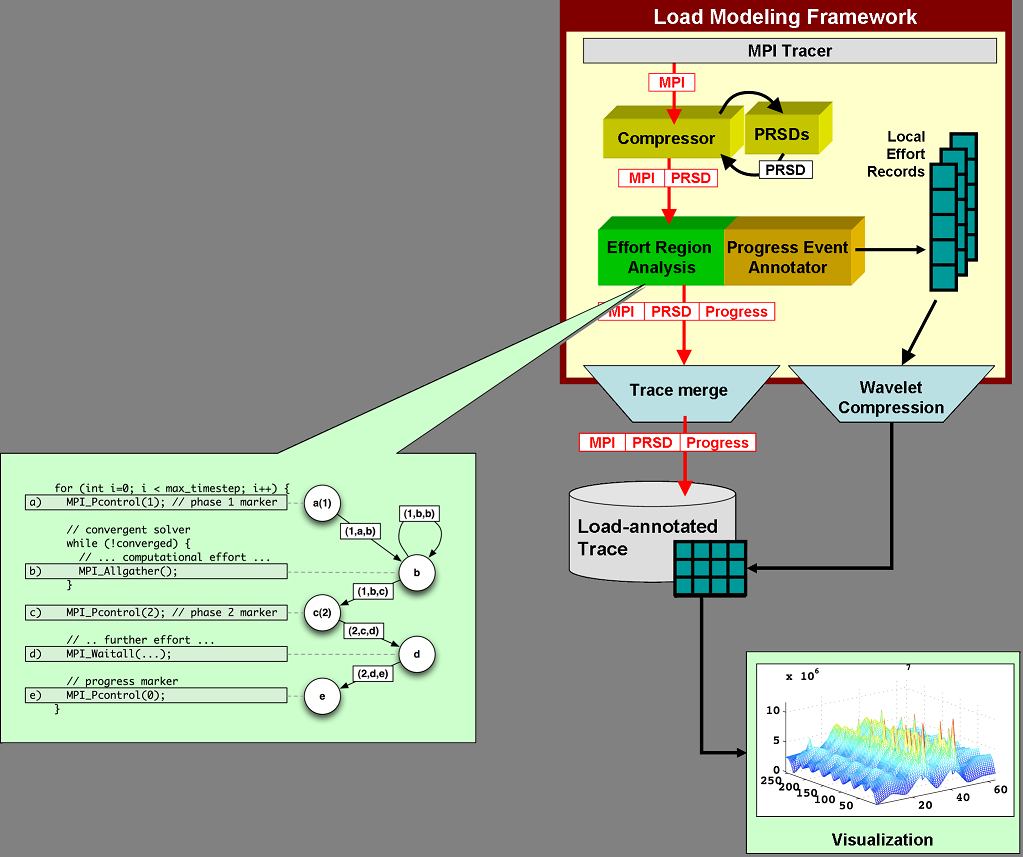
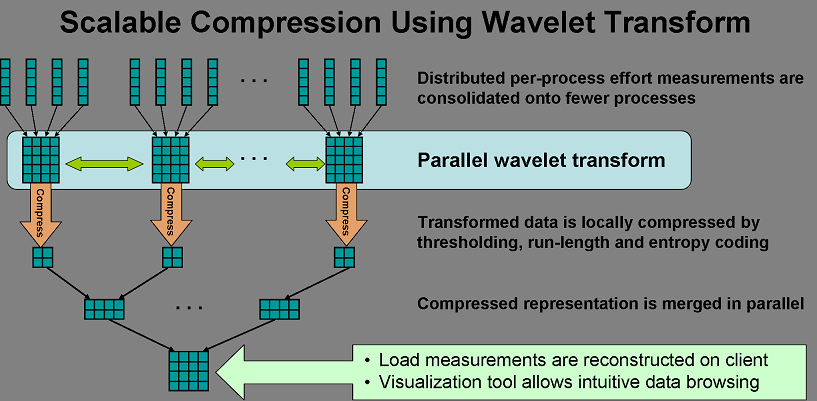
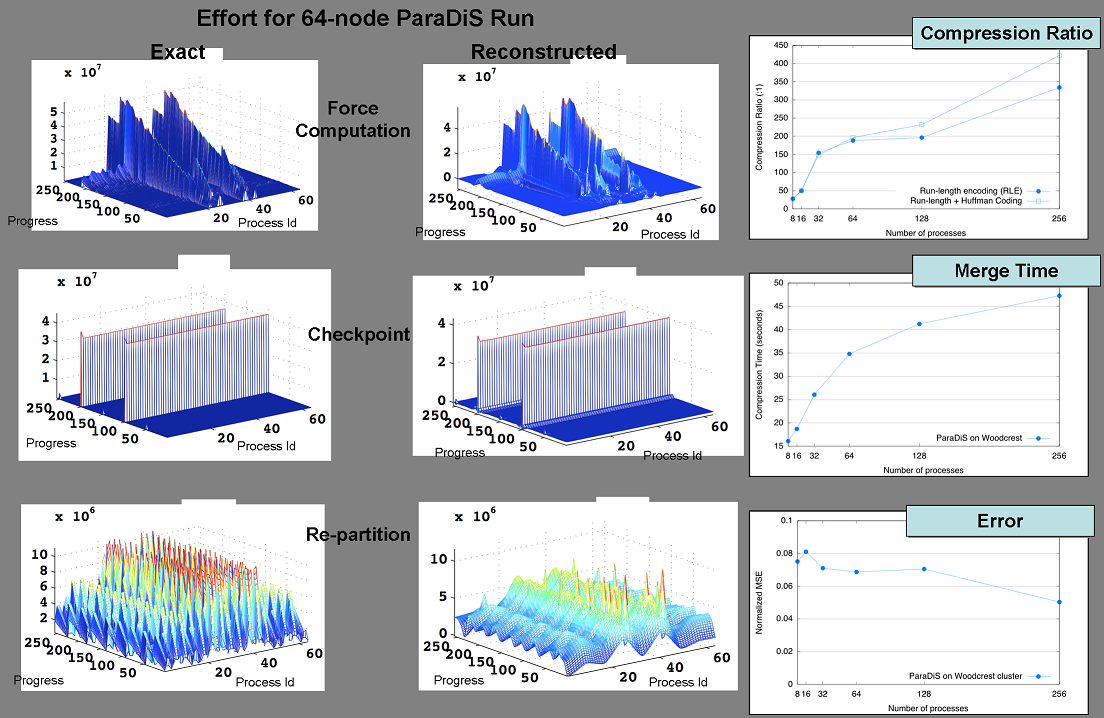
Evolutionary Load-Balance Analysis with Scalable Data Collection
|
Idea: Normalize measurements and models based on application semantics Progress loops
Effort loops
Progress instrumentation
Effort modeled with code regions
|
|
|
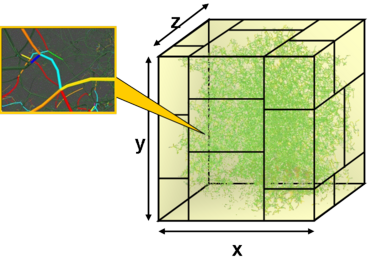
Load Balance in ParaDiS
Models dislocation dynamics in crystals
|
|
Future Directions
Flexible framework for application-specific tools
Near term