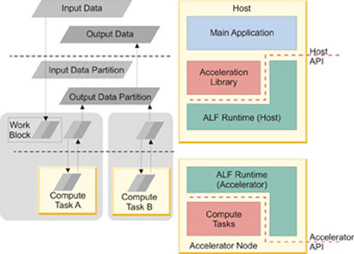
Within the ALF framework, a computational kernel is defined as an accelerator routine that takes a given set of input data and returns the output data based on the given input, see Figure 1. The input data and the corresponding output data are divided into separate portions, called work blocks. For a single task, ALF allows these work blocks to be processed in parallel.
With the provided ALF API, you can also create descriptions for multiple compute tasks, and define their execution orders by defining their dependencies. Task parallelism is accomplished by having tasks without direct or indirect dependencies between them. The ALF runtime provides an optimal parallel scheduling scheme for the provided tasks based on the given dependencies.