The following two simple examples show the usage of overlapped I/O buffers.
Both examples do matrix addition.
- The first example implements C=A+B, where A, B, and C are different matrices. There are three separate matrices on the host for matrix a, b, and c.
- The second example implements A=A+B, where matrix A is overwritten by the result. Storage is reserved on the host for matrix a and matrix b. The result of a+b is stored in matrix b.
Figure 1. The two overlapped I/O buffer samples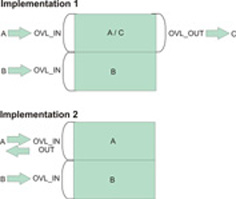
Matrix setup
Note: The code is similar to the matrix_add
example, see Matrix add - host data partitioning example. Here only the
relevant code listing is shown.
/* ---------------------------------------------- */
/* matrix declaration for the two cases */
/* ---------------------------------------------- */
#ifdef C_A_B // C = A + B
alf_data_int32_t mat_a[ROW_SIZE][COL_SIZE]; // the matrix a
alf_data_int32_t mat_b[ROW_SIZE][COL_SIZE]; // the matrix b
alf_data_int32_t mat_c[ROW_SIZE][COL_SIZE]; // the matrix c
#else // A = A + B
alf_data_int32_t mat_a[ROW_SIZE][COL_SIZE]; // the matrix a
alf_data_int32_t mat_b[ROW_SIZE][COL_SIZE]; // the matrix b
#endif
Work block setup
This code segment shows the work
block creation process for the two cases.
for (i = 0; i < ROW_SIZE; i+=PART_SIZE){
if(i+PART_SIZE <= ROW_SIZE)
wb_parm.num_data = PART_SIZE;
else
wb_parm.num_data = ROW_SIZE - i;
alf_wb_create(task_handle, ALF_WB_SINGLE, 0, &wb_handle);
#ifdef C_A_B // C = A + B
// the input data A and B
alf_wb_dtl_begin(wb_handle, ALF_BUF_OVL_IN, 0); // offset at 0
alf_wb_dtl_entry_add(wb_handle, &mat_a[i][0], wb_parm.num_data*COL_SIZE, ALF_DATA_INT32); // A
alf_wb_dtl_entry_add(wb_handle, &mat_b[i][0], wb_parm.num_data*COL_SIZE, ALF_DATA_INT32); // B
alf_wb_dtl_end(wb_handle);
// the output data C is overlapped with input data A
// offset at 0, this is overlapped with A
alf_wb_dtl_begin(wb_handle, ALF_BUF_OVL_OUT, 0);
alf_wb_dtl_entry_add(wb_handle, &mat_c[i][0], wb_parm.num_data*COL_SIZE, ALF_DATA_INT32); // C
alf_wb_dtl_end(wb_handle);
#else // A = A + B
// the input and output data A
alf_wb_dtl_begin(wb_handle, ALF_BUF_OVL_INOUT, 0); // offset 0
alf_wb_dtl_entry_add(wb_handle, &mat_a[i][0], wb_parm.num_data*COL_SIZE, ALF_DATA_INT32); // A
alf_wb_dtl_end(wb_handle);
// the input data B is placed after A
// placed after A
alf_wb_dtl_begin(wb_handle, ALF_BUF_OVL_IN, wb_parm.num_data*COL_SIZE*sizeof(alf_data_int32_t));
alf_wb_dtl_entry_add(wb_handle, &mat_b[i][0], wb_parm.num_data*COL_SIZE, ALF_DATA_INT32); // B
alf_wb_dtl_end(wb_handle);
#endif
alf_wb_parm_add(wb_handle, (void *)&wb_parm, sizeof(wb_parm)/sizeof(unsigned int), ALF_DATA_INT32, 0);
alf_wb_enqueue(wb_handle);
}
Accelerator code
The accelerator code is shown here. In both cases, the output sc can be set to the same location in accelerator memory as sa and sb./* ---------------------------------------------- */
/* the accelerator side code */
/* ---------------------------------------------- */
/* the computation kernel function */
int comp_kernel(void *p_task_context, void *p_parm_ctx_buffer,
void *p_input_buffer, void *p_output_buffer,
void *p_inout_buffer, unsigned int current_count,
unsigned int total_count)
{
unsigned int i, cnt;
int *sa, *sb, *sc;
my_wb_parms_t *p_parm = (my_wb_parms_t *) p_parm_context;
cnt = p_parm->num_data * COL_SIZE;
sa = (int *) p_inout_buffer;
sb = sa + cnt;
sc = sa;
for (i = 0; i < cnt; i ++)
sc[i] = sa[i] + sb[i];
return 0;
}