SPE programs use DMA transfers to move data and instructions between main storage and the local store (LS) in the SPE.
- Start a DMA data transfer from main storage to buffer B in the LS.
- Wait for the transfer to complete.
- Use the data in buffer B.
- Repeat.
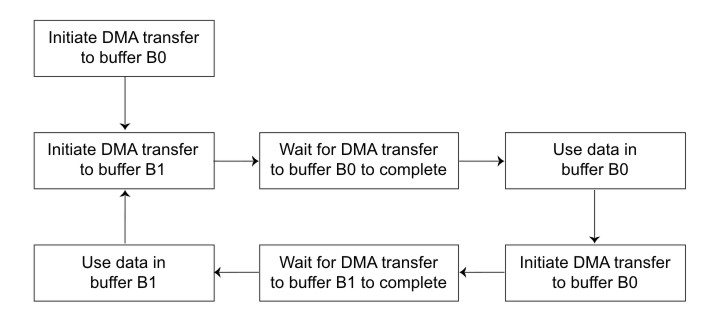
This method wastes a great deal of time waiting for DMA transfers to complete. We can speed up the process significantly by allocating two buffers, B0 and B1 , and overlapping computation on one buffer with data transfer in the other. This technique is called double buffering. Figure 1 shows a flow diagram for this double buffering scheme.
Double buffering is a form of multibuffering, which is the method of using multiple buffers in a circular queue to overlap processing and data transfer.
/* Example C code demonstrating double buffering using
* buffers B[0] and B[1]. In this example, an array of data
* starting at the effective address eahi|ealow is DMAed
* into the SPU's local store in 4-KB chunks and processed
* by the use_data subroutine.
*/
#include <spu_intrinsics.h>
#include "spu_mfcio.h"
#define BUFFER_SIZE 4096
volatile unsigned char B[2][BUFFER_SIZE] __attribute__ ((aligned(128)));
void double_buffer_example(unsigned int eahi, unsigned int ealow, int buffers)
{
int next_idx, buf_idx = 0;
// Initiate DMA transfer
spu_mfcdma64(B[buf_idx], eahi, ealow, BUFFER_SIZE, buf_idx, MFC_GET_CMD);
ealow += BUFFER_SIZE;
while (--buffers) {
next_idx = buf_idx ^ 1;
// Initiate next DMA transfer
spu_mfcdma64(B[next_idx], eahi, ealow, BUFFER_SIZE, next_idx, MFC_GET_CMD);
ealow += BUFFER_SIZE;
// Wait for previous transfer to complete
spu_writech(MFC_WrTagMask, 1 << buf_idx);
(void)spu_mfcstat(MFC_TAG_UPDATE_ALL);
// Use the data from the previous transfer
use_data(B[buf_idx]);
buf_idx = next_idx;
}
// Wait for last transfer to complete
spu_writech(MFC_WrTagMask, 1 << buf_idx);
(void)spu_mfcstat(MFC_TAG_UPDATE_ALL);
// Use the data from the last transfer
use_data(B[buf_idx]);
}
To use double buffering effectively, follow these rules for DMA transfers on the SPE:
- Use multiple LS buffers.
- Use unique DMA tag IDs, one for each LS buffer or logical group of LS buffers.
- Use fenced command options to order the DMA transfers within a tag group.
- Use barrier command options to order DMA transfers within the MFC's DMA controller.
The purpose of double buffering is to maximize the time spent in the compute phase of a program and minimize the time spent waiting for DMA transfers to complete. Let τt represent the time required to transfer a buffer B, and let τc represent the time required to compute on data contained in that buffer. In general, the higher the ratio τt/τc, the more performance benefit an application will realize from a double-buffering scheme.