![]()
![]()
![]()
![]()
![]()
![]()
Results
To verify that our tool is able to correctly instrument Gprof profiling, we
compared the profiles of three applications instrumented with our tool against
the profiles of these applications compiled with the -pg option specified. See
table 1 for more details on the applications profiled. For each application
profiled we will show (1) a side by side comparison of the Gprof call graph for
our tool and a -pg version, (2) a graph of the time spent break down for our
tool and a -pg version, and (3) a brief commentary about the profiles. The first
application compared was the micro benchmark originally written to test
correctness in stages 2 and 3 of our implementation. We deemed this benchmark
the easiest to profile because it did no real work, and was written as a quick
test of our concepts.
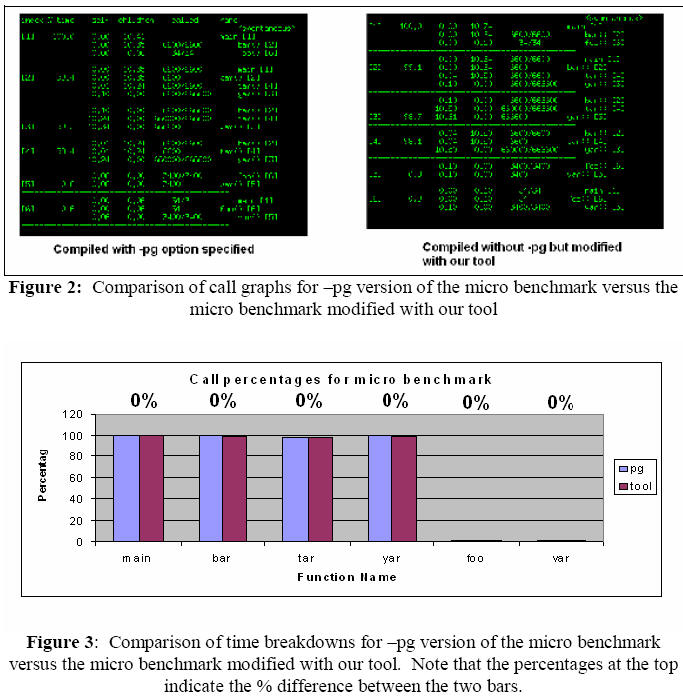
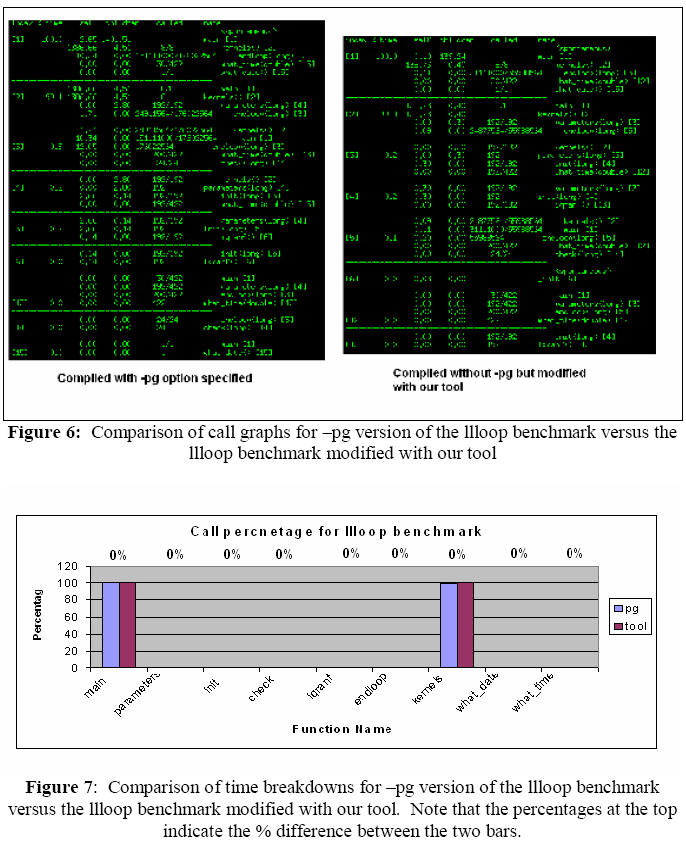
In both figures 2 and 3 we see that for the micro
benchmark, our tool performs flawlessly. The call graphs match in the -pg
version and our tool. There is also no difference between the call percentages
either. The second application compared was the LINPACK benchmark. This
benchmark was introduced by Jack Dongarra as a floating point performance
benchmark. It is far more complex than our micro benchmark in that it actually
does work. This benchmark is not the most complex because it was written for far
slower computers and only runs for less
than 1 second.
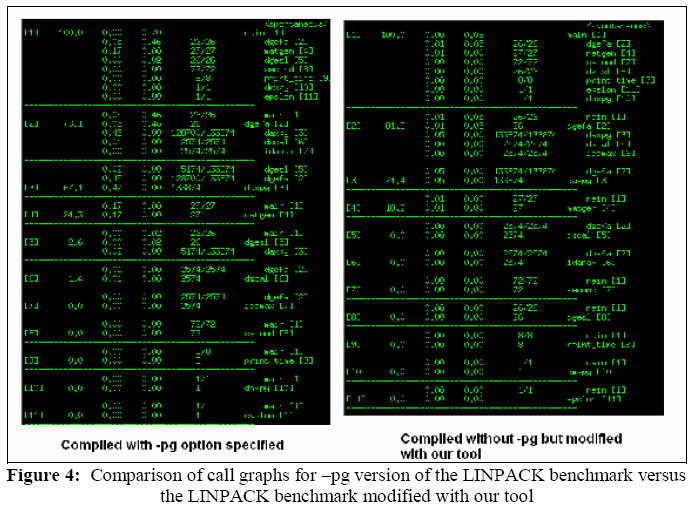
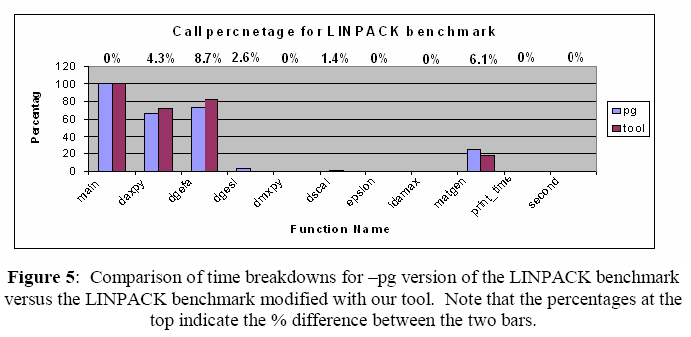
In both figures 4 and 5 we see that for the LINPACK benchmark, our tool performs well (but not perfect on the percentages). The call graphs match in the -pg version and our tool. There are slight differences between the call percentages. We attribute this percentage difference to machine load and a difference in the cost of the original mcount and our modified mcount. The third application compared was llloop. This benchmark is the most complex benchmark used. It does real work, has many function calls, and runs for a long time. This was the most strenuous test for our tool.