In order to test and compare the performance of
programs compiled using the enhanced pseudo language framework a simple program
with a number of computations within a test for loop is implemented using both
the traditional FOR loop and also the PARALLELFOR loop. These programs
were then organized and compiled with an increasing number of loop iterations
(and data elements) to compare/analyze the execution time as a function of
elements/(loop size). The CUDA access library mentioned above was
compiled with a hard-coded thread block size of 100 specified in a linear block
definition so the loops smaller than 100 load a number of threads greatly
exceeding those needed. These tests have been compiled and executed
using test sizes ranging from 0 to 100000 and the results are illustrated in
the chart below.
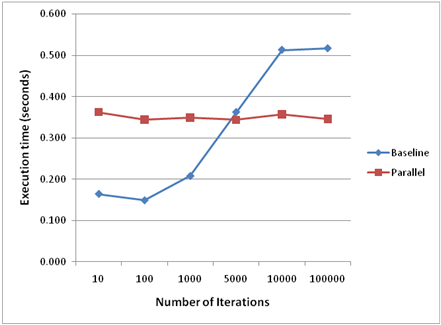
The figure above graphically shows the execution time for
both the serial (baseline) and parallel execution modes. From the chart,
one can easily see that the serial execution time is linearly proportional to
the number of data elements/iterations, where as the parallel execution are
essentially constant. It is important to note here that the pseudo
language has no support for outputting the system time so the time markers used
are outside the execution of the java VM within the test script itself.
Because of this, the java loading overhead is included in the execution times
for both the serial and parallel execution results. Also, the parallel
versions incur a one-time overhead for loading the shared libraries. This
overhead should not be too significant, but it should be noted in the results.
In any event, the parallel execution mode demonstrates good performance compared
to t he serial versions. Considering
the lack of optimizations and a somewhat inefficient data movement design this
is quite remarkable. Had the purpose of
this effort been to optimize the performance results, these figures could have
been drastically improved.
|