The following section describes the specific features proposed for the PTX backend developed in this study
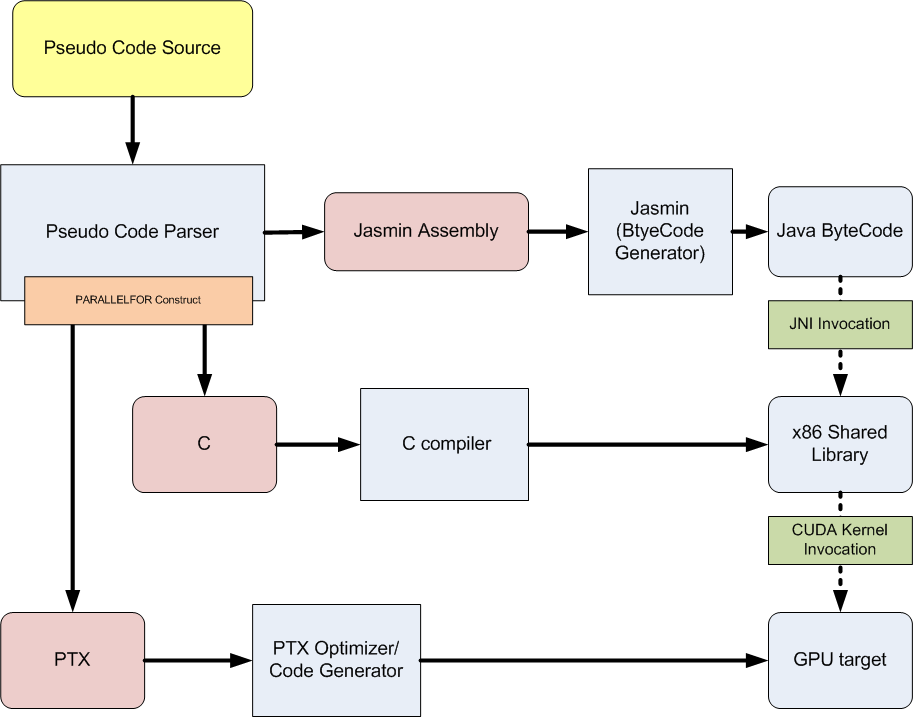 As determined during the review phase, the JNI interface to invoke the CUDA kernel would be best implemented using a common (shared) native interface that does not have to be recompiled for each Pseudo language program. In addition, the initial research of the changes required to generate PTX modules for the code executed within the PARALLELFOR loops it has been determined that the basic structure of the Pseudo language front end would make it difficult to determine which lines should be included in the PTX module at the time they are parsed. Because at the time the PARALLELFOR is encountered all of the statements contained within are encapsulated in a single inherited attribute, it would be best to find a method to generate the PTX modules from the Jasmin Assembly that is contained within the statements attribute. At present, a proposed addition is to generate Jasmin Assembly (in a unique module) from these statements contained in the inherited attribute. This code can then be compiled into Java byte code which is readily available for LLVM byte code generation. As mentioned in the initial proposal, this LLVM byte code can then be used to generate the PTX modules. Below is an updated illustration showing these changes in the Pseudo language framework. 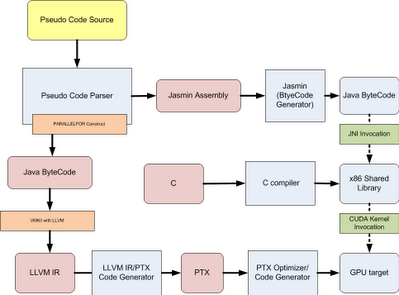 |
Proposed PTX Backend features |