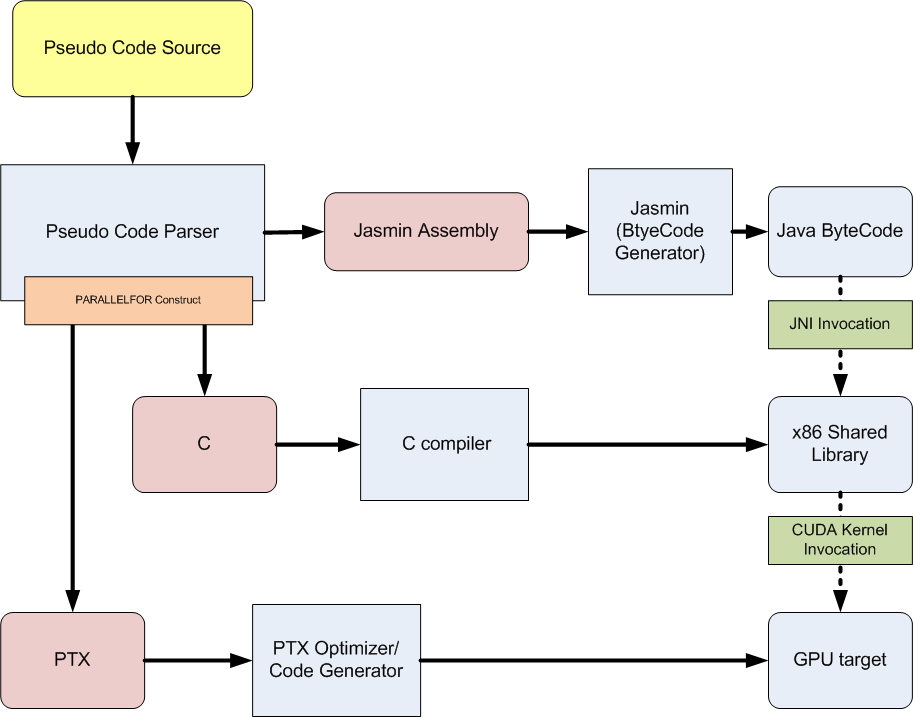
While it
may be desirable to utilize several open source compiler tools to manage PTX
module generation, the current state of these tools and LLVM add-ons are not
such that they can be integrated in a project with a short development
cycle. Instead the tools included with
the CUDA SDK have been utilized to generate the PTX modules via output from the
compiler front end. The compiler front
end has been separated into two parts: the first pass generates the host code,
and the second generates a .cu module.
This .cu source is then used to generate a .ptx module. The figure below demonstrates the process of code
generation and shows which tools are referenced.
This design minimizes the number modules generated for each
pseudo language program and also limits the tool requirements to a manageable
set. One limitation which should be
noted in the current version is that the number of PTX modules (and therefore
the number of parallel loops) for each program is limited to one. This limitation is easily resolved by
numbering the parallel loops and then generating the corresponding PTX modules;
however, not having this functionality does not prevent the validation of these
concepts.
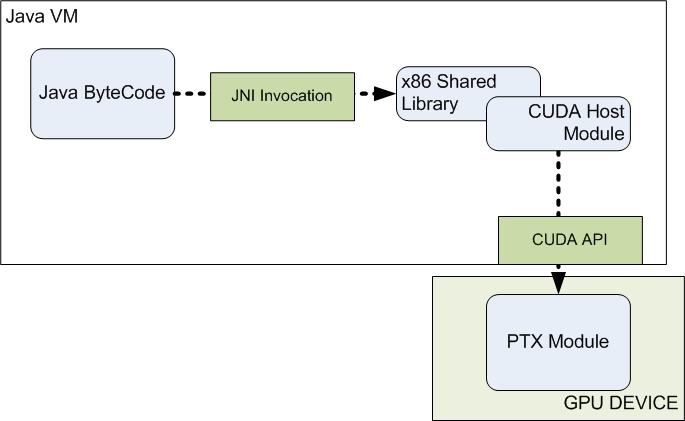
At run time, a pre-compiled native library is accessed by
the host byte code whenever a parallel for loop is encountered. This native library then loads the ptx module
dynamically and
invokes the device function. A key feature of this
design is that the native method can be implemented with a completely generic
interface and thus not recompiled for each pseudo language program. The parameters for this interface include the
data, the iteration boundaries and the PTX module name. The figure below shows the run time framework
used by the pseudo language programs.
 In
this design, the native library (indicated by “x86 Shared Library”) and the
CUDA Host module are both pre-compiled and not modified with each pseudo
language programs. The only property
contained within these modules is the thread block size. The number of blocks is then a function of
the thread block size and the number of iterations in the loop (Max/Thread
Blocks). Prior to module invocation, the
data for each pseudo language program is copied to a 2D Java array which is
then copied again to a linear C array.
This C array contains the host memory which is then copied to the GPU
device prior to launching the device function.
The PTX module references these data values using offsets based on the
specified size of each array within the pseudo language program. The frontend compiler has been modified to
take the maximum array size as a parameter which is used for both copying data
as well as specifying the data offsets in the PTX module. After
the device function is complete, the data is then copied back in reverse order
to the original pseudo language variables
|