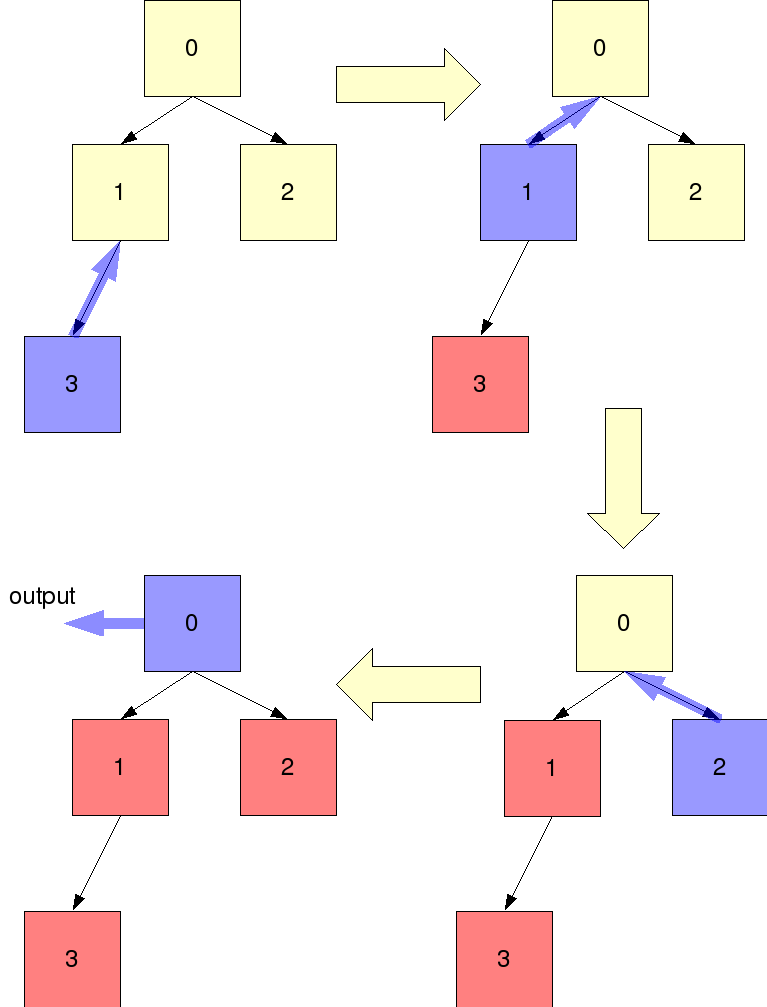
The nodes are arranged in a binary tree (radix tree). The node '0' acts as the root node. This tree is such that to determine the left and right children of a node, one needs to only know the id of the node. So this tree is not physically constructed with pointers. The tree is virtual, and children of every node are computed at the end for aggregation only.
To perform internode compression a binary tree based recursive mechanism is used. Each node waits on its children to send their trace queues (flattened out rsd_queues). The bottom of the tree does not wait on anyone, because their children's id's are greater than the number of nodes in the communication world. They simply flatten their rsd queues and send them to their parents. Each node retrieves queues from its children, aggregates the child queues with its own trace queue. It then flattens it and sends it to its parent. The root node writes out its queue onto its global buffer instead of flattening and sending its information to its parent.
Clearly looking at the intra-node and internode compression techniques, it is obvious that the timing aggregating systems for both these techniques would be different.