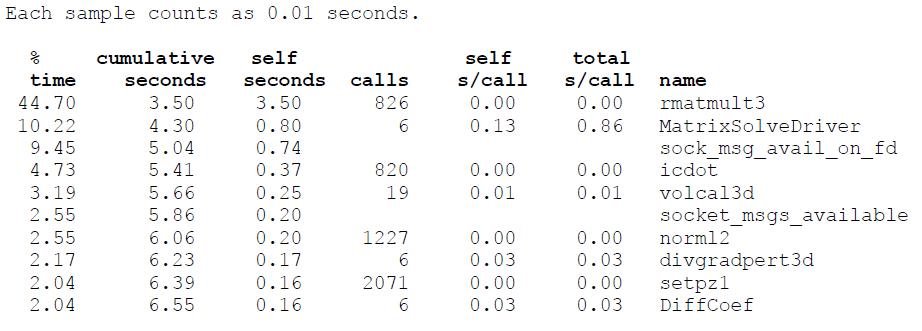
Runtime Analysis of IRS benchmark on Henry 2 In order to analyze the current behavior of this benchmark, we ran it on Henry 2 cluster using MPI for communication and gprof [6] for profiling the execution time. Please see the table below for the top 10 functions in terms of the execution times.
 Proposed Solution
We can see that above 10 functions make up for 83.64% of the total execution times at each node. We plan to accelerate the above 10 functions using the multi-processing capability of the IBM cell processors [5]. Each cell processor has 1 PPE and 8 SPEs (6 SPEs on Sony PS cell processor [4]). The main processing happens on the PPE. We plan to do functional and domain partitioning of the above functions and run them on multiple SPEs. From the above table, we can see that rmatmult3 and MatrixSolveDriver are responsible for more than 55% of the total computation, forming the biggest hotspots within the benchmark. These functions deal with matrices and can be easily parallelized using the techniques studied in the course.
We downloaded the IRS benchmark version 1.0 from the LLNL website. We modified different Makefiles and some perl scripts to change the compilation to use powerpc compilers, compiler / linker options, include / library paths etc. Finally we could build the working IRS benchmark which could run on the PSXX machines. We also enabled MPI and the gprof [6] instrumentation on the IRS and got the execution profile of the benchmark on IBM Cell processor. Note that at each processor, the IRS runs only on the PPE. |
{kind=link}