I have several updates regarding the project.
Optimizations
First, it occurred to me that I had not really optimized the serial code for the CPU it was running on. The CPU has 2 cores, and I had not inserted OpenMP pragmas into the code to take advantage of that. So I put in OMP parallel for pragmas before the outer loop of every subroutine that is looped in the main time step while loop: flux_x, update_x, flux_z, update_z, source, and boundaries. I tried with OMP_NUM_THREADS set to 1, 2, and 4. The optimal value on this processor was 2, and it came very close to a speed-up of 2.
I also made an optimization to both the serial and CUDA codes where I took out a pow(…,2) and performed the squaring with multiplication instead. Evidently pow() takes a lot of cycles to complete because the runtimes were substantially lower. Because of this observation, I took pains to remove as much duplication of pow() statements (in both serial and CUDA codes) as possible, and this further reduced the runtime quite a bit. The serial code which previously ran at 460 seconds now runs at 198 seconds.
Code Corrections
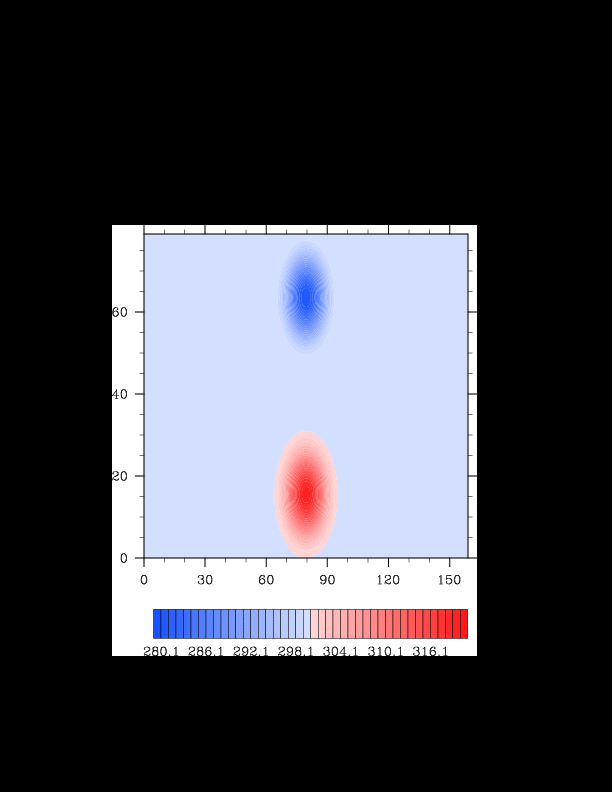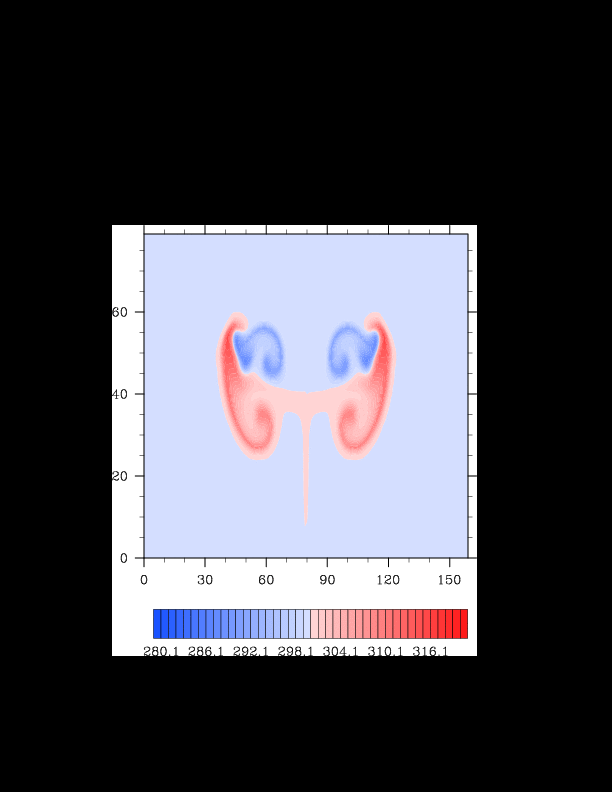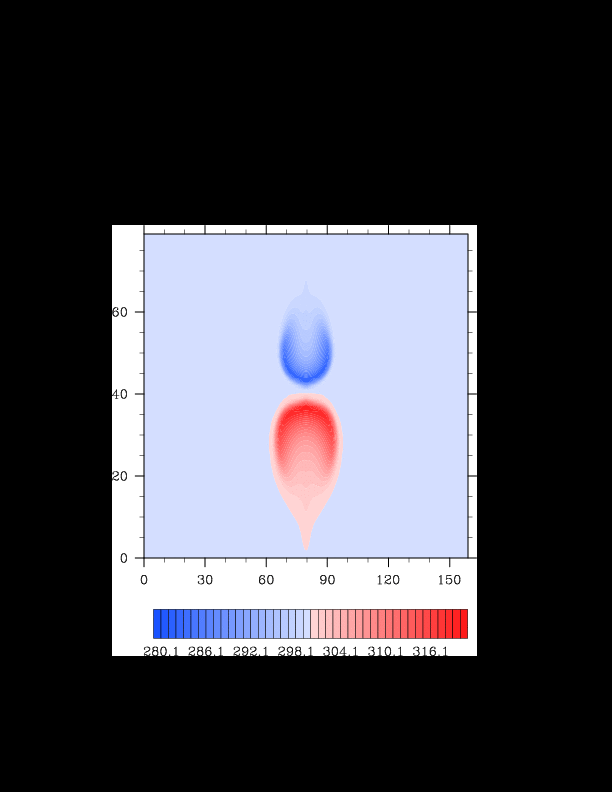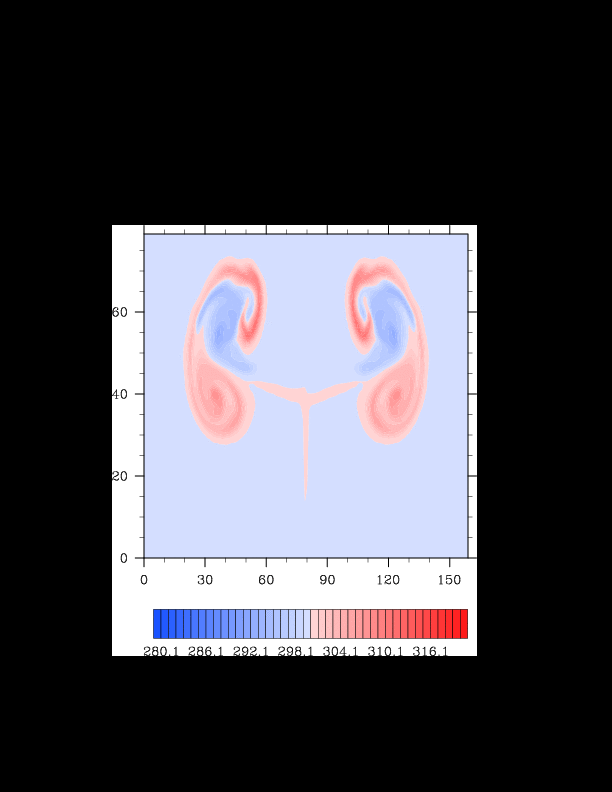
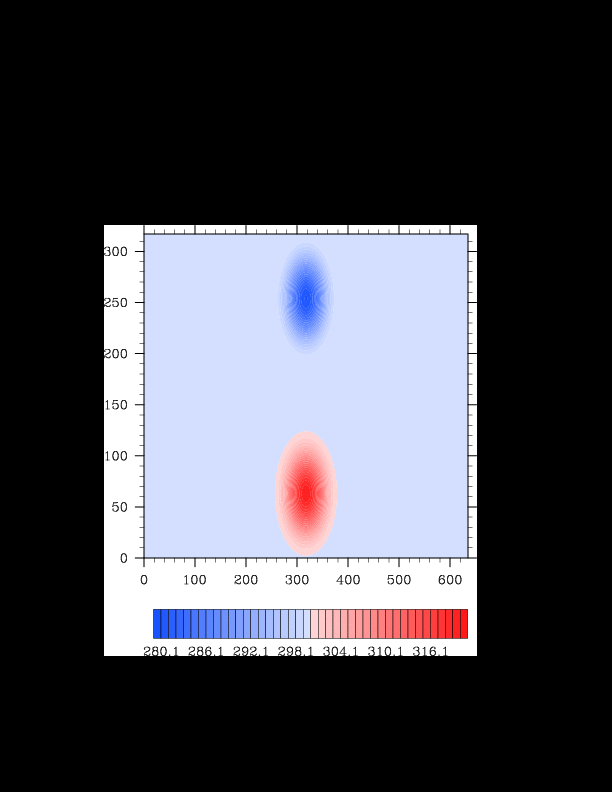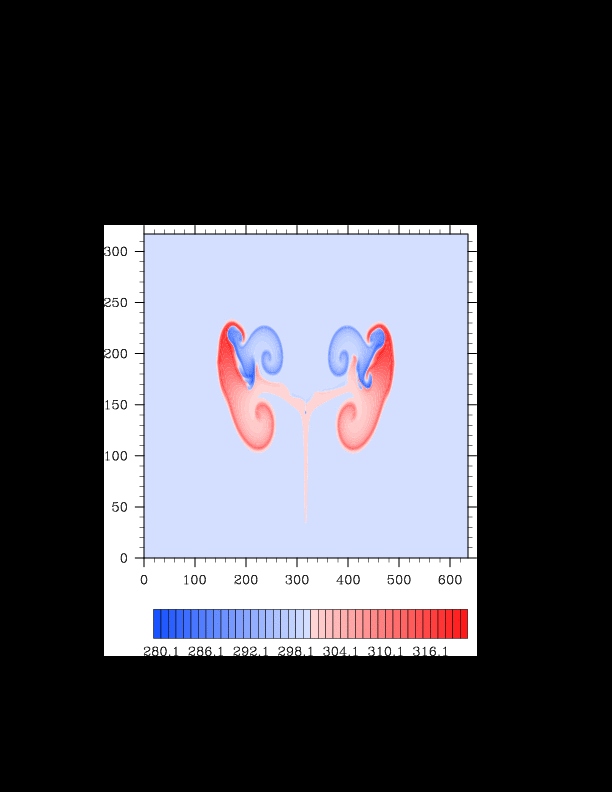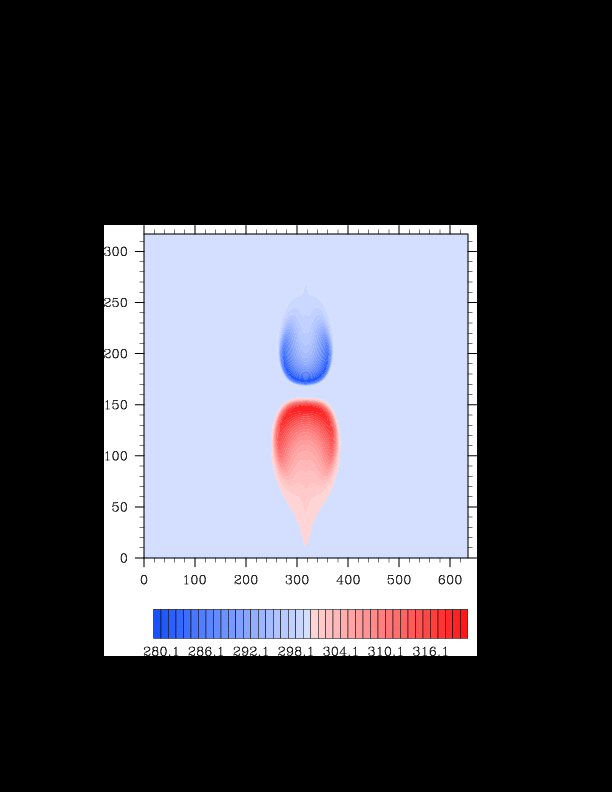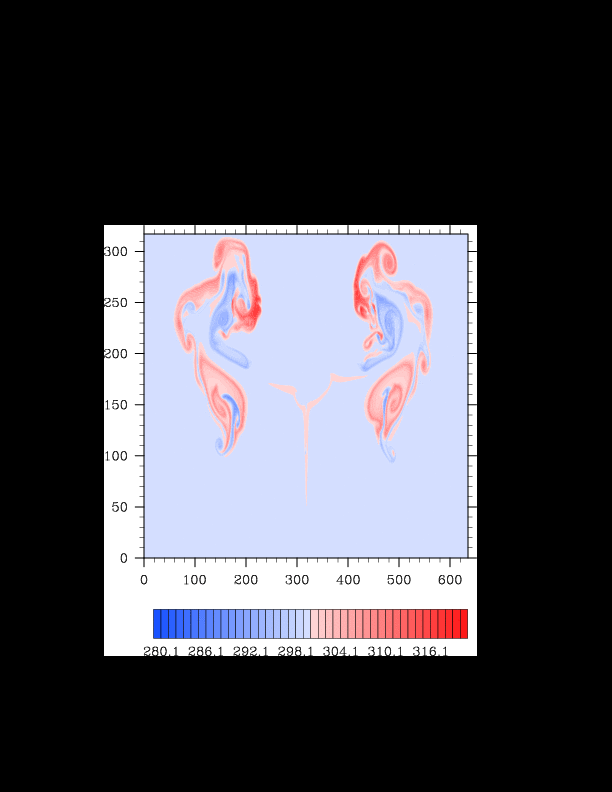
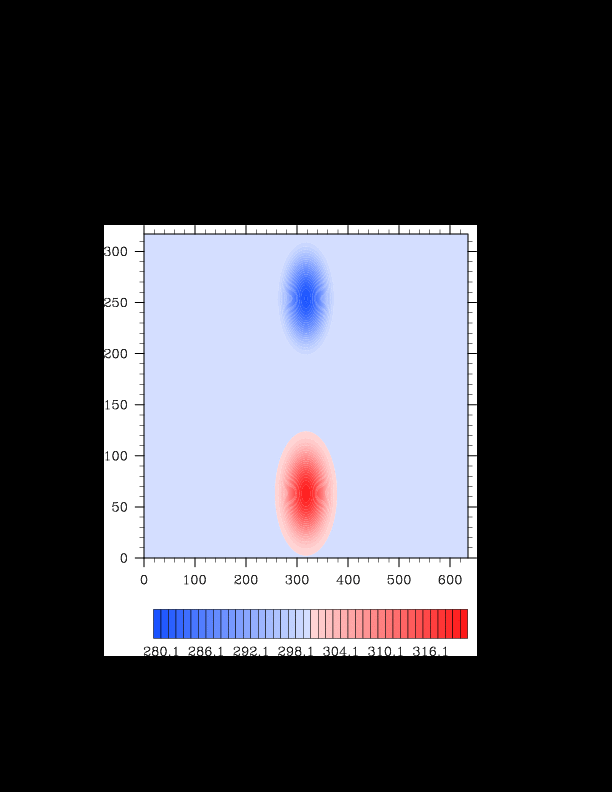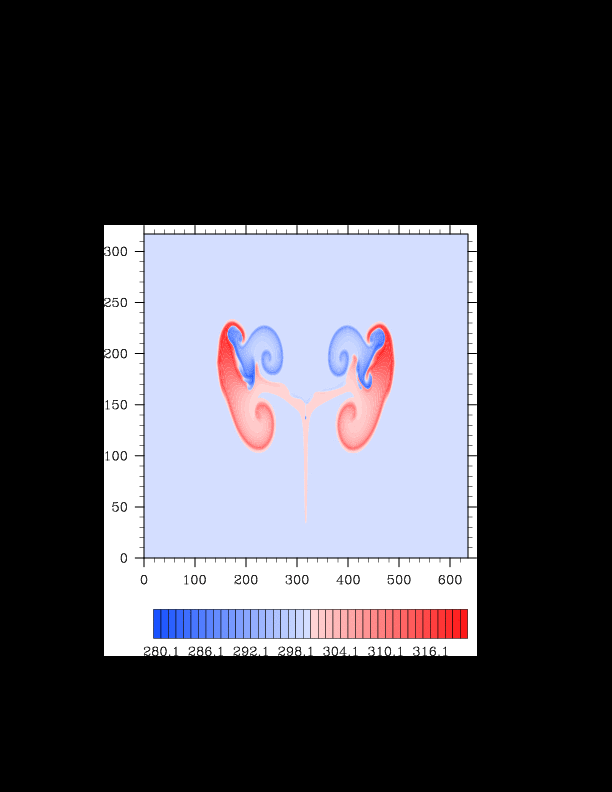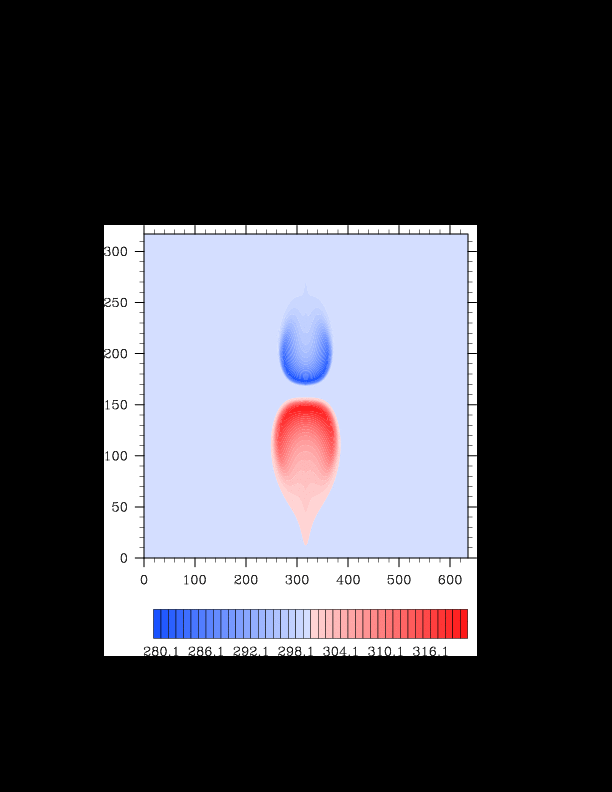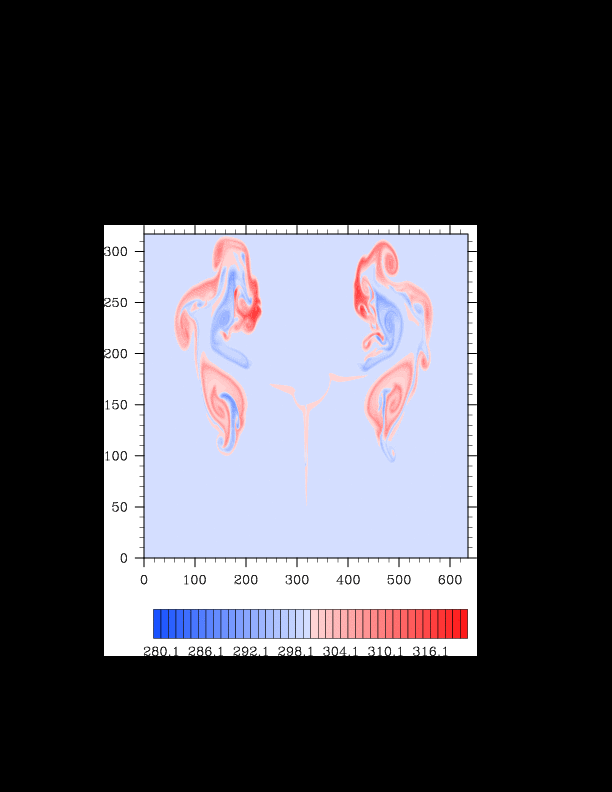
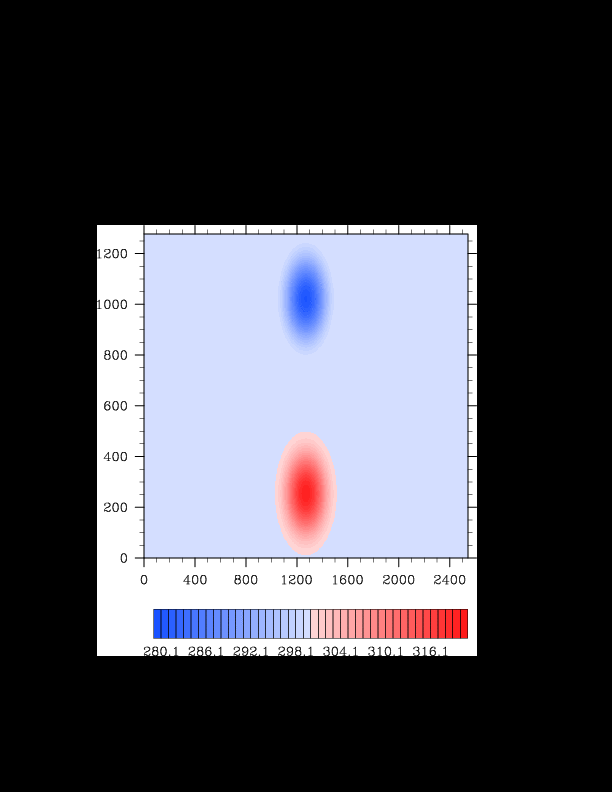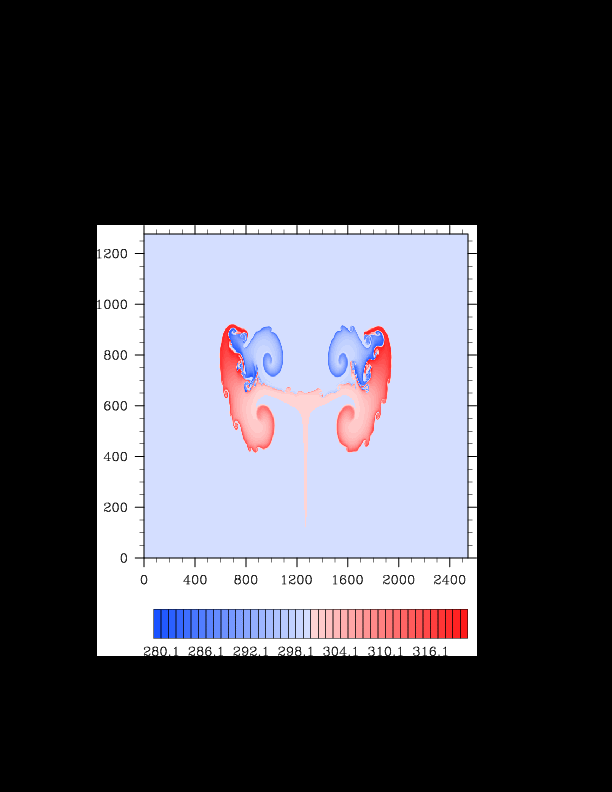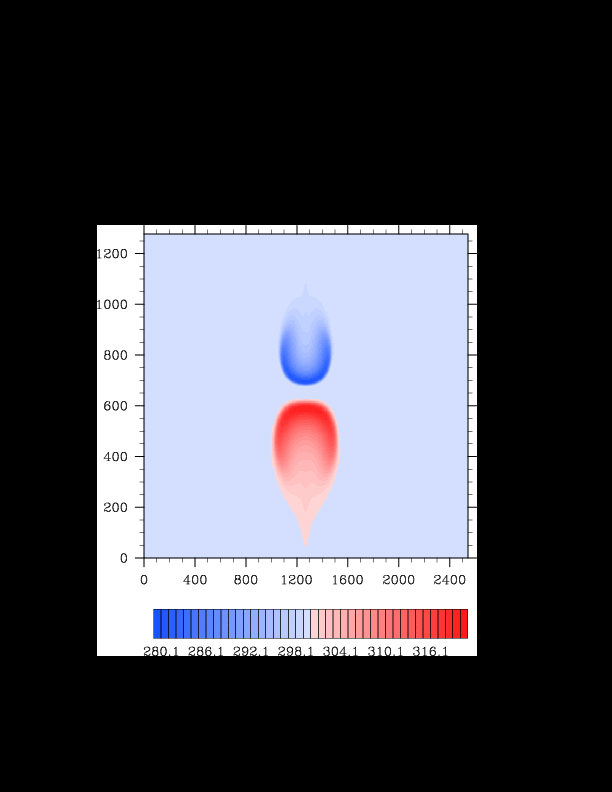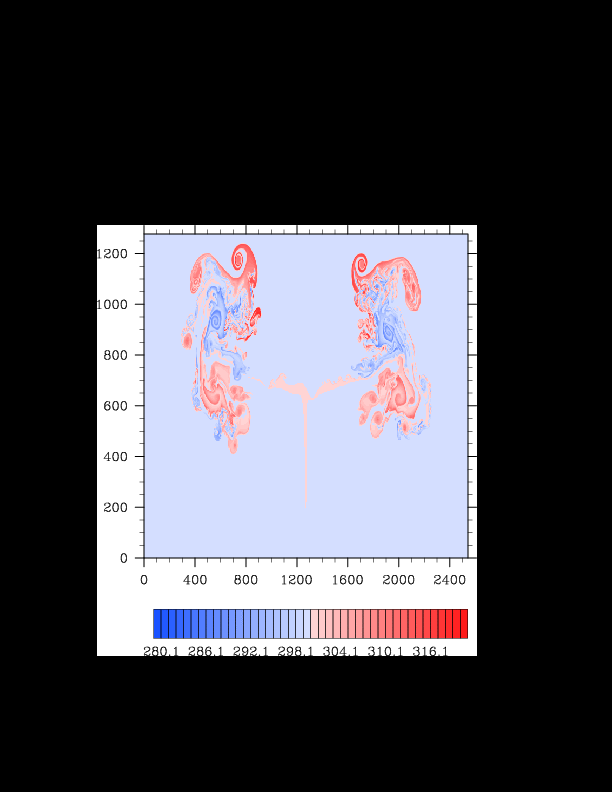
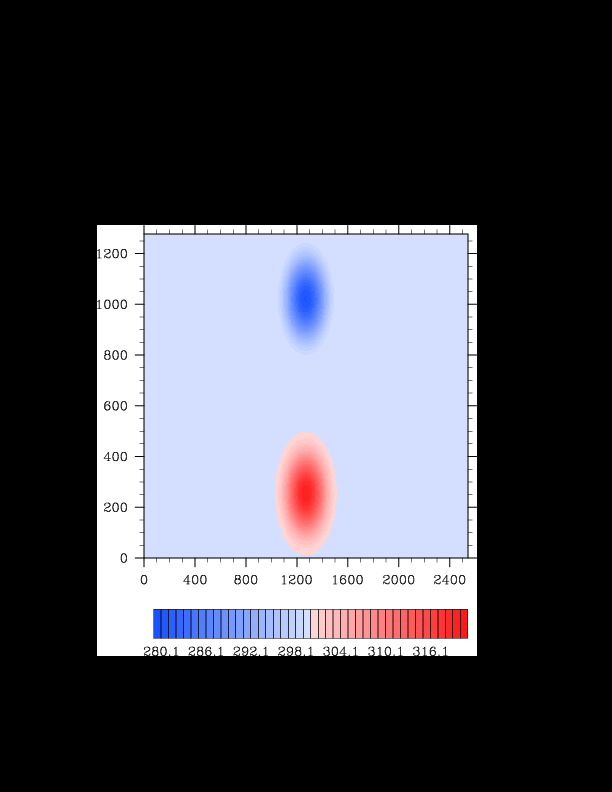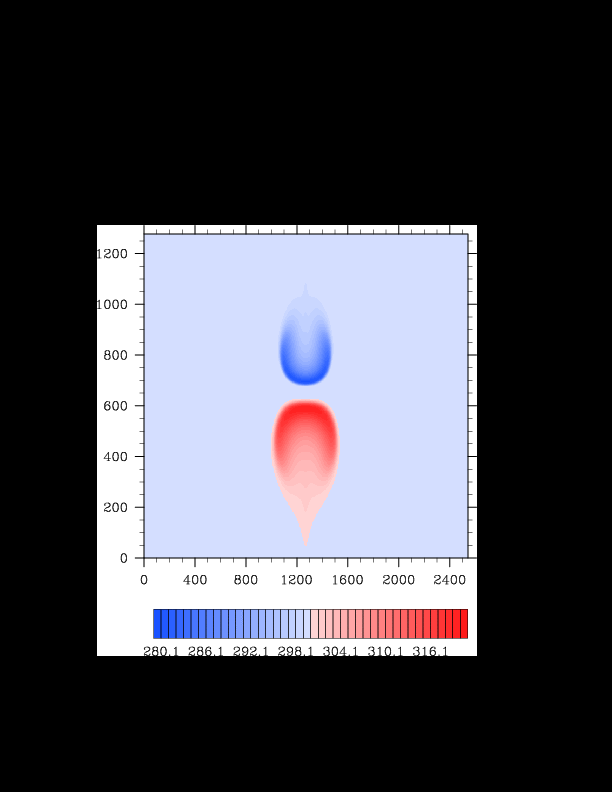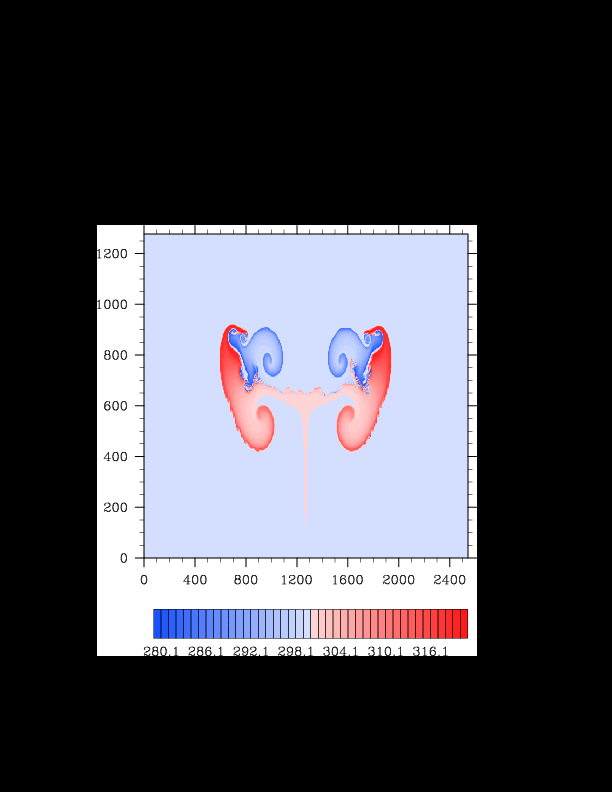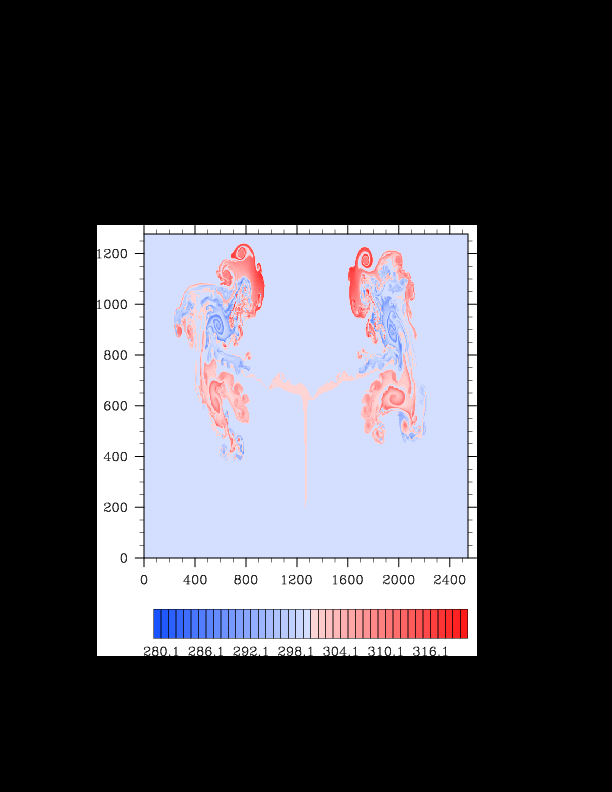
I finally found the reason for the asymmetry in my results. It was a surprisingly bad error that gave surprisingly realistic results. In the flux computation, I perform Gaussian quadrature to integrate over an interval. I made the mistake of integrating out over the wrong interval, so when I fixed this, the solution was finally symmetric (at least in double precision). I realized that single precision does lead to some pretty pronounced asymmetries, so I changed my mind again and decided the solution must be in double precision for accuracy purposes. The flow I am using for the project is turbulent, and in turbulent (and therefore chaotic) flows, any (even machine precision) difference will amplify into visible differences later in the solution. The classic example of this is the Lorenz attractor.
CUDA-Specific Optimizations
I’ve had some fairly surprising results as far as CUDA optimizations in general. First, running with a maximum of 128 registers allocated per thread (via a compiler flag) and using 128 threads per block (16×8) was actually slower than running with 64 registers per thread and 256 threads per block (16×16). The reason this is surprising is that running with 64 registers actually uses significantly more local memory (which is very slow and uncached) in a given thread than running with 128. Evidently, 256 threads better hides the memory latency and better fills the device.
I also discovered the joys of loop unrolling with the #pragma unroll directive. I found that the compiler will not unroll a loop if the pow() function is called. It complains that unexpected control flow occurred and refuses to unroll. The faster yet less accurate __powf() function will work with unrolling, but not the pow() function. After some testing, I concluded that the inaccuracy due to the CUDA __powf() function was not worth the performance gain. Even though the loop unrolling increased the amount of local memory used, it gave an 8% gain in efficiency.
New Speed-Up Values
With the new optimizations, the serial code on a 160 x 80 grid runs in 198 seconds. The double precision CUDA code on a 680 x 320 grid runs in 736 seconds. This gives a speed-up of just over 17x on a single GPU. It is apparent that 4 GPUs will not give the 64x speed-up I wanted from the beginning because from prior experience, the speed-up is highly sub-linear for small problems. I may need to go to 1360 x 640 to get that speed-up on 4 GPUs. Because there is less computation in the kernel available to hide memory latency, the single-precision CUDA version only gave a 24x speed-up. Relative to the double precision speed-up, this is less than before. So the speed advantages of going with single precision are less pronounced.
Overall Thoughts for Single-GPU Optimizations
For a scientist who is interested in a good speed-up without the hassle of overly tedious optimizations, I would say to pay attention to the following:
- Make sure you have enough threads per block to hide memory latencies (at least 128, but 256 may be better)
- Make sure you have enough blocks to fill the device. On the GTX 280, there are 3 clusters of 10 SMPs which means you need at least 30 blocks, but preferably many, many more.
- If you have read-only constants, declare them as __shared__, making sure you don’t overflow the available 16Kb per block. Use the -Xptxas compile flag to output to console how much shared memory a kernel will use per thread (multiply this by the number of threads per block in the kernel launch for total shared memory use).
- Unroll loops whenever possible. I doubt you’ll overflow local memory.
- For me, it was worth it to run 256 threads per block rather than 128 if possible. Use the compile flag –maxrregcount to limit the number of registers per thread. You have 16K registers per block and 16Kb of shared memory per block on the GTX280, so ensure on your specific GPU to obey its constraints. I tried –maxrregcount 32 with 512 threads per block, but this was slower than 256 threads per block.
- If you can use single precision, do so. It will likely be a factor of 2x faster than the speed-up with doubles. But make sure it doesn’t unacceptably degrade accuracy.
Obviously if you have a linear algebra issue, don’t reinvent the wheel. Use cuBLAS or something similar. But if you have a kernel with fairly simple (and repeated) access to global memory, go ahead and coalesce the reads into shared memory and work within shared memory. In my case, it simply wasn’t worth the effort because the code would have become very difficult to understand and maintain. If it’s not simple, I say just let the compiler coalesce your reads for you and work in global memory. If your global memory ends up in local variables, and most of your kernel works on those local variables (as was the case with my main kernels), I have to believe the compiler is smart enough to know to allocate those variables as registers, so it may not be beneficial to explicitly declare them as shared. In fact, when I tried to do this, it degraded performance.
As for porting code to the GPU. If you have a loop structure like
for (i = 0; i < NX; i++) {
for (j = 0; j < NY; j++) {
It is easiest to convert it for use in a kernel as
ii = blockIdx.x*blockDim.x + threadIdx.x;
jj = blockIDx.y*blockDim.y + threadIdx.y;
for (i = ii; i < NX; i+=gridDim.x*blockDim.x) {
for (j = jj; j < NY; j+=gridDim.y*blockDim.y) {
This way, you know all of the work is getting done, and it places the burden of optimization on ensuring that NX and NY are multiples of 32 or have a division remainder as close to 32 as possible to make sure all warps are optimally productive.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}