CSC 548 Fall 2009, under Dr. Frank Mueller
| Team Member Name |
Email id |
| Kaustubh Prabhu |
ksprabhu AT ncsu DOT edu |
| Narayanan Subramanian |
nsubram AT ncsu DOT edu |
| Ritesh Anand |
ranand AT ncsu DOT edu |
Problem Description:
Assessing the benefits of CUDA accelerator on AMG2006 Benchmark of ASC Sequoia
AMG2006 is a parallel algebraic multi-grid solver for linear systems arising from problems on unstructured grids [1].
This benchmark is an SPMD C code which uses MPI [1] (extensively) and openMP constructs. There was a performance study done some time back on OpenMP for this application, but a full exploitation of threading is still to be done [2]. Due to this SPMD paradigm and its usage of data parallelism by forming logical sub-problem data grids we see tremendous scope for making use of NVIDIA CUDA accelerator which bases its parallelism on similar lines.
NVIDIA CUDA is general purpose programming architecture that facilitates usage of parallel processing capabilities of a class of GPUs (mostly from NVIDIA) in general purpose programming rather than restricting it to graphics processing [3].
Through our extensive searching over www, we have concluded that none such CUDA implementation for the AMG2006 benchmark exists that we are aware of at this point in time.
The following table represents the head to head execution time comparison with and without CUDA kernel execution. The concerned function is hypre_BoomerAMGRelax.
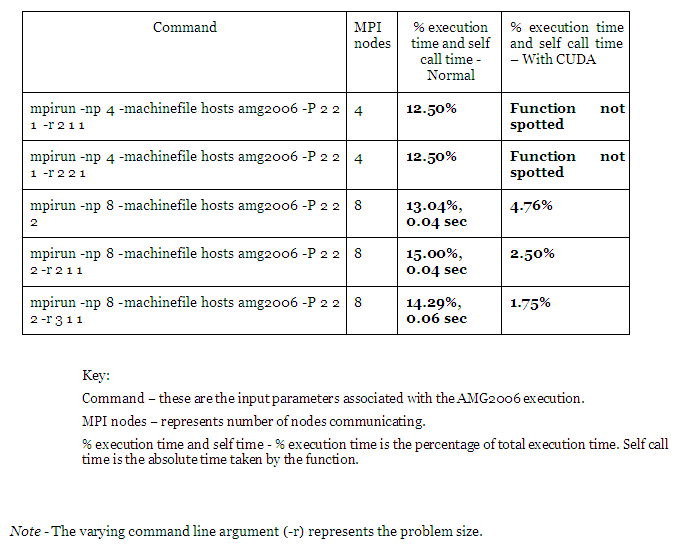
Conclusion
We have observed a performance improvement in function execution time when the application AMG2006 was ported to CUDA. Due to memory constraints we could not exploit this at higher problem size. Hence the observed speedup is limited for less problem size and relatively fewer numbers of nodes.
This work attempts to assess the speedup obtained by employing parallelism capabilities of general purpose graphic processing unit in NVIDIA graphics cards, using CUDA, on AMG2006 which is a MPI C code parallel algebraic multi-grid solver for linear systems arising from problems on unstructured grids.
In our analysis we also found that AMG2006 is memory-access bound, doing only about 1-2 computations per memory access, so memory-access speeds will have a large impact on performance. This observation is also made in the read me of the benchmark. Knowing that this hardware accelerator in GeForce GTX 280 is tuned towards data-parallel compute extensive tasks, like in graphics rendering, we do not expect this to be extracting much speedup on this benchmark. We expect it to actually show a fractional speedup.
The main reasons are -
1. Huge data structures (matrices, vectors, etc.) are to be worked upon by the Kernel.
2. Due to the size of data structure we cannot leverage spatial locality optimally as size of cached constant and texture memory supported is rather limited.
3. The accessing pattern of data structures is very irregular. Array indices are often stored as values in some other array, hence the strides in access very unpredictable. E.g. one of the array access inside kernel is a[b[i]] where a[i] and b[i] are both device arrays.
4. We fall back on global memory access, which are time expensive and on top of it, computation to I/O ratio is very unfavorably biased.
However, keeping in mind these limitations we have achieved
1. Integration of CUDA kernel and AMG2006 application
2. Speedup in function execution time, which involves the computation kernel
3. A method which can be applied to port any computational kernel on CUDA
For this, we have used GeForce GTX 280 NVIDIA graphics cards available on the osXX machines having AMD Athlon XP processors. We have been able to completely port the benchmarking applications on CUDA. One of the identified compute intensive kernels has been successfully ported on CUDA. Currently, we can observe speedup in function execution (through gprof).
Since our last reported progress, in which we had correctly identified the main performance bottlenecks which could be optimized, following are the main solved issues:
1. Compiling AMG2006 on CUDA cluster
2. Porting whole application to CUDA
3. Porting compute intensive performance bottlenecks to CUDA kernels
4. Running AMG2006 applications with CUDA (limited semantics)
5. Optimizing CUDA code for lesser problem size
We began the work from performance analysis of AMG2006 on regular AMD Athlon XP cluster. We could find the performance bottlenecks and hence the targets for optimization. This is aptly captured in our previous reports and on our project web page.
Below we describe the major tasks undertaken and how we solved it, with issue faced if any.
1 Compiling:
This was our first r0ad block. After 2 weeks of almost continuous effort we were able to successfully compile AMG2006 applications with CUDA.
Problems Faced:
Compiling the AMG2006 application involved multiple Makefiles. Integration of application specific makefiles and CUDA makefiles was main blockade. As our code was creating a custom library file, integration of makefile was difficult. The CUDA programming structure doesnt accept relative path for included library files.
What worked:
nvcc compiler provided by CUDA. nvcc allowed us to create object files for custom libraries.
2 Porting whole application:
Our approach to port to CUDA was:
(1) Identifying kernel regions (code sections to be executed on the GPU)
(2) Extracting kernel regions and transforming them into CUDA kernel functions, and
(3) Analyzing shared data that will be accessed by the GPU and inserting necessary memory transfer calls.
Problems Faced:
Identification of computational kernels which can be successfully ported to CUDA. Many of the computational kernels involved custom library calls like (HYPRE_CTAlloc) which can not be ported to CUDA. Some of the hot spots had to be ignored because of this device specific constraint.
What worked:
Any loops with multiple entry-exit points were rejected. Any compute intensive code with a custom library call was rejected. The elimination method proved useful.
3 Porting Kernels:
Problems Faced:
A) Primary concern was memory constraints while creating device specific data structures. As the problem size of application increased, CUDA memory was insufficient.
B) The application accesses non uniform array patterns. This involves heavy usage of array[array[offset]] pattern. This creates limitation on the memory access.
C) The size of device specific arrays is hard to find. Furthermore, due to complex structure of the code, it was difficult to access the size of device specific arrays. This is still the Major obstacle.
What worked:
A) We limited our scope to optimize the performance of AMG2006 for reduced problem size.
B) Overprovision of memory is a simple approach we have used in this code. Another possible approach is to access the relevant code section, where the arrays are getting populated and return the size. This will involve changing the code.
4 Optimization:
By optimization we mean the performance improvement in execution time of the compute intensive kernel, and respective improvement in function execution time. We have observed that the function execution time reduces drastically. CUDA computes the kernel much faster but also involves copying of huge data structures.
Problems Faced:
The memory constraints on the device specific data structures did not allow us to exploit CUDA kernels for large problem size.
We were able to solve the issue only to certain extent, given the scope of the project.
The benchmark has many applications within this like Laplace, 27pt, Stencil, Linear, Solver, etc. We observed that on doing a weak scaling, we could find some hotspots where there is scope for computational improvement. Some results with problem scaling on varied large number of processing element are available in the amg2006.readme [1]. We will be comparing those trends with what we observe employing CUDA.
Though our initial analysis using GNU profiling tool gprof [4] we observe that there can be many performance bottlenecks, as some compute intensive functions are consuming a lot of total application time.
This optimization will be done by porting those methods (excluding library and initialization ones) in CUDA.
For computing the 3D laplace on a cube and the 27-point stencil problem, we came up with a list of methods that consistently become the bottleneck of execution. On doing a code walkthrough, we found that they are composed of simple c code with iterative structures acting on huge data list. We believe such code blocks can be speeded up by using the concept of GPU threads, which is likely to result in a better performance.
After profiling the application AMG2006 for successive runs, we find the following functions could be the performance bottleneck -
| functions |
Frequency of occurrence |
| hypre_BoomerAMGBuildCoarseOperator* |
10 |
| hypre_BoomerAMGCoarsen* |
9 |
| hypre_BoomerAMGBuildInterp |
7 |
| hypre_BoomerAMGRelax* |
6 |
| hypre_BigBinarySearch^ |
3 |
| hypre_CSRMatrixMatvec |
2 |
* Functions consistently show up as bottlenecks, indentified by repeated runs for considerable size.
^ Function now removed from potential bottleneck, as it is called a lot of times and hence the overall time taken is large.
Some other result logs can be seen here.
Some Loop analysis results:
hypre_BoomerAMGBuildCoarseOperator (AMG2006/parcsr_ls/par_rap.c)
| Line No. |
Type of Loop |
Nested |
Level of nesting |
Remarks |
| 541- 741 |
for |
Yes |
5 |
Type1 |
| 768-1021 |
for |
Yes |
5 |
Type1 |
| 1148- 1376 |
for |
Yes |
5 |
Type1 |
| 1427-1747 |
for |
Yes |
5 |
Type1 |
hypre_BoomerAMGRelax (AMG2006/parcsr_ls/par_relax.c)
| Line No. |
Type of Loop |
Nested |
Level of nesting |
Remarks |
| 189-211 |
for |
Yes |
2 |
Type1 |
| 223-247 |
for |
Yes |
2 |
Type1 |
| 303-324 |
for |
Yes |
2 |
Type1 |
| 336-359 |
for |
Yes |
2 |
Type1 |
| 425-464 |
for |
Yes |
3 |
Type2 |
| 470-491 |
for |
Yes |
2 |
Type1 |
| 511-552 |
for |
Yes |
3 |
Type2 |
| 607-655 |
for |
Yes |
3 |
Type2 |
hypre_BoomerAMGCoarsen (AMG2006/parcsr_ls/par_coursen.c)
| Line No. |
Type of Loop |
Nested |
Level of nesting |
Remarks |
| 628-827 |
for |
Yes |
3 |
Single Bottleneck |
1.) Do a profiling for this application and gather the statistics. Observe trends and scope for optimization.
2.) Run the application for different problem sizes, different processor topologies, and different applications.
3.) List those functions which consume more computational time. Omit the library functions and the set up related functions.
4.) Study the functions and port them independently on CUDA.
5.) Integrate the ported functions with the application
6.) Run, profile and compare the results to observe trend and draw conclusions.
| Tasks |
Deadline |
Assignment |
Status |
| 1.) Profiling and Bottlenecks identification |
11/10/09 |
All |
Complete |
| 2.) Initial Proting to CUDA with minimal changes |
11/13/09 |
All |
Complete |
| 3.) Application optimization design |
11/15/09 |
Applications divided among members |
Complete |
| 4.) Application optimized implementation |
11/22/09 |
Functions divided among members |
Complete |
| 5.) Modified Application profiling |
11/24/09 |
All |
Complete |
| 6.) Reiteration if needed |
11/26/09 |
All |
Complete |
| 7.) Drawing results and conclusions |
11/27/09 |
All |
Complete |
Future work involves addition of more computational kernels in AMG2006 application, which were identified in earlier report. Also a scalable approach while accessing device specific data structures is required.
Code Related:
Modified Source Code tar
Makefile
Instructions to run
Reports:
Report 1
Report 2
Final Report
1.) Read Me for AMG2006 available in AMG C source tar
2.) ASC Sequoia AMG Benchmark summary
3.) What is NVIDIA CUDA
4.) GNU profiler "gprof"