The ALF accelerator runtime code provides handles to the following different buffers for each instance of a task:
- Task context buffer
- Work block parameter and context buffer
- Work block input data buffer
- Work block output data buffer
- Work block overlapped input and output data buffer
Task context buffer
A task context buffer is used by applications that require common persistent data that can be referenced and updated by all work blocks. It is also useful for merging operations or all-reduce operations. A task is optionally associated with one task context buffer. You can specify the size of the task context buffer through the task descriptor creation process. If the size of the task context buffer is specified as zero (0) in the task descriptor, there is no task context associated with the any of the tasks created with that task descriptor.
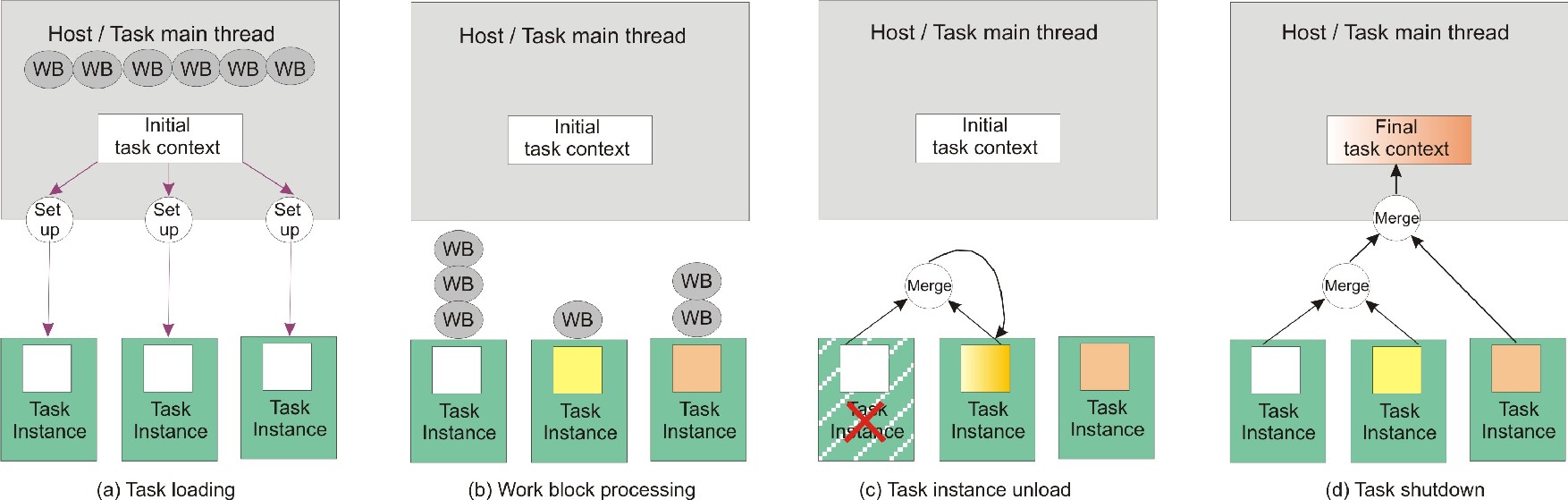
The lifecycle of the task context is shown in Figure 1. To create the task, you call the task creation function alf_task_create. You provide the data for the initial task context by passing a data buffer with the initial values. After the compute task has been scheduled to be run on the accelerators, the ALF framework creates private copies of the task context for the task instance that is running.
You can provide a function to initialize the task context (alf_accel_task_context_setup) on the accelerator. The ALF runtime invokes this function when the running task instance is first loaded on an accelerator as shown in Figure 1 (a).
All work blocks that are processed by one task instance share the same private copy of task context on that accelerator as shown in Figure 1 (b).
When the ALF scheduler requests an accelerator to unload a task instance, you can provide a merge function (alf_accel_task_context_merge), which is called by the runtime, to merge that accelerator's task context with an active task context on another accelerator as shown in Figure 1 (c).
Work block parameter and context buffer
- It passes work block-specific constants or reference-by-value parameters
- It reserves storage space for the computational kernel to save the data specific to one work block, which can be either a single-use work block or a multi-use work block
For more information, see Modifying the work block parameter and context buffer when using multi-use work blocks.
Work block input data buffer
The work block input data buffer contains the input data for each work block (or each iteration of a multi-use work block) for the compute kernel. For each iteration of the ALF computational kernel, there is a single contiguous input data buffer. However, the data for the input buffer can come from distinct sections of a large data set in host memory. These separate data segments are gathered into the input data buffer on the accelerators. The ALF framework minimizes performance overhead by not duplicating input data unnecessarily. When the content of the work block is constructed by alf_wb_dtl_entry_add, only the pointers to the input data chunks are saved to the internal data structure of the work block. This data is transferred to the memory of the accelerator when the work block is processed. A pointer to the contiguous input buffer in the memory of the accelerator is passed to the computational kernel.
For more information about data scattering and gathering, see Data transfer list.
Work block output data buffer
This buffer is used to save the output of the compute kernel. It is a single contiguous buffer in the memory of the accelerator. Output data can be transferred to distinct memory segments within a large output buffer in host memory. After the compute kernel returns from processing one work block, the data in this buffer is moved to the host memory locations specified by the alf_wb_dtl_entry_add routine when the work block is constructed.
Work block overlapped input and output data buffer
The overlapped input and output buffer (overlapped I/O buffer) contains both input and output data. The input and output sections are dynamically designated for each work block.
This buffer is especially useful when you want to maximize the use of accelerator memory and the input buffer can be overwritten by the output data.
For more information about when to use this buffer, refer to When to use the overlapped I/O buffer.
For an example of how to use the buffer, see Overlapped I/O buffer example.