Results
The results of the tests are as shown. The main comparison is of performance variation with using CUDA.
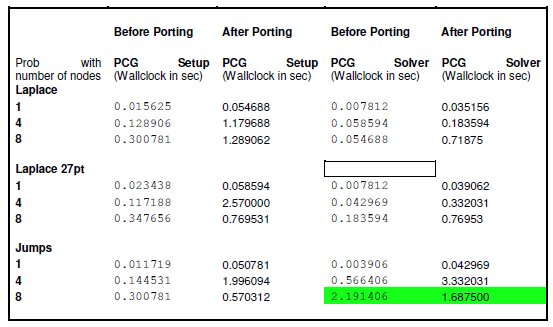
The above table shows the performance of AMG before and after porting it to CUDA. The measurements have been done for all three problem types Laplace, Laplace 27pt and Jumps. We found that with jumps there is a slight improvement with using CUDA. The reason we believe this is because of the decrease in the memory transfer sizes due to sparse matrices when run with the “Jumps” option. There is performance degradation in “Laplace” and “Laplace27pt” option. We found the amount of time the calls took at the modified hotspots and separated the time run inside cuda and the memory transfer time.
The graph depicts the time for coarseshiftinterp (hotspot 1) function when coded on host and with CUDA. It also shows the time spent in allocating and releasing memory on the GPU device. X-axis shows number of iterations for which the function call is made.
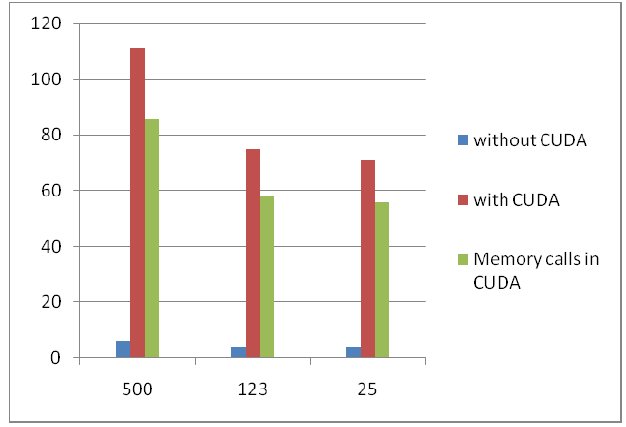
Figure 1 Execution Times (sec) for the coarseshiftinterp function
We have also ported the Binary search on CUDA (hotspot 2). The results below shows the wallclock times of the function call before and after porting to CUDA.
| Iterations | without CUDA | with CUDA |
| 100 | 8 | 425 |
| 50 | 5 | 213 |
Inner Product of matrix is also ported on CUDA (hotspot 3). For 1000 iterations, kernel call takes 664microsec as compared to 3microsec on the host machine.
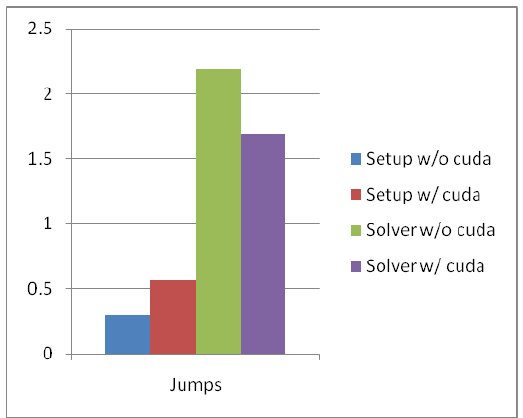
Figure 2 Execution Times (sec) for AMG for Jumps
The graph above shows the execution times (Wallclock) for the Jumps problem before and after porting the AMG code to CUDA.
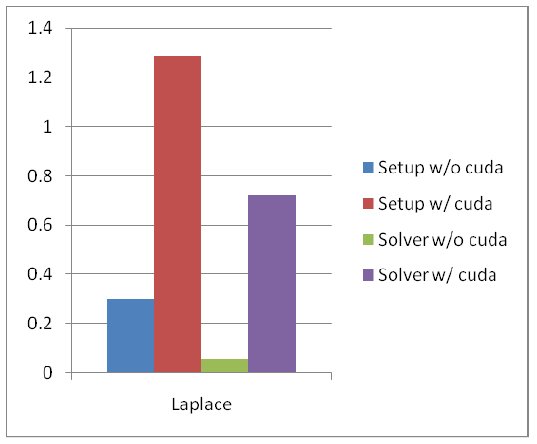
Figure 3 Execution Times (sec) for AMG for Laplace
The graph above shows the execution times (wallclock) for the Laplace problem before and after porting the AMG code to CUDA.

Figure 4 Execution Times (sec) for AMG for Laplace 27pt
The graph above shows the execution times (wallclock) for the Laplace27pt problem before and after porting the AMG code to CUDA.